4 Distribuciones de frecuencias y representaciones gráficas
En esta práctica contiene ejercicios que muestran como hacer un resumen descriptivos de un conjunto de datos mediante la construcción de tablas de frecuencias y la representación gráfica de las mismas. En particular, se muestra cómo construir los siguientes tipos de gráficos:
- Diagramas de barras.
- Diagramas de sectores.
- Diagramas de cajas.
- Histogramas.
- Polígonos de frecuencias.
4.1 Ejercicios Resueltos
Para la realización de esta práctica se requieren los siguientes paquetes:
NotaVersiones de R y de los paquetes utilizados
TipContexto para Copilot
Si se va a usar Copilot para resolver los ejercicios se recomienda añadir el siguiente contexto al comienzo del script o al fichero r.instructions.md.
---
name: "Reglas de programación para R"
applyTo: "**/*.[rR], **/*.qmd"
---
## Reglas de programación para R
- Usar tidyverse para todas las tareas de preprocesamiento (dplyr/tidyr/readr/stringr/lubridate/forcats/purrr).
- Preferir tuberías con |> (o %>% si se usa en el archivo).
- Evitar la manipulación de datos en base R (merge, aggregate, subset) a menos que se solicite explícitamente.
- Mantener el código legible y usar verbos explícitos: select, mutate, summarise, group_by, pivot_longer/wider.
- Cuando no haya ambigüedad no antepongas el nombre del paquete a la función.
- En los nombres de variables y valores respetar el uso de mayúsculas y minúsculas (camelCase o snake_case) y ser consistente en todo el código.
- No generar nuevos data frames, ni modificar los asistentes, salvo cuando se indique explícitamente.
- Utiliza el prefijo `df_` para los nombres de los data frames.
- Organizar las salidas con la función tidy del paquete broom y mostrar solo las columnas relevantes (estimate, std.error, statistic, p.value).
- Mostrar los data frames o las tablas con la función kable del paquete knitr.
- Para gráficos usar ggplot2 y mantener un estilo limpio y profesional.Ejercicio 4.1 En una encuesta a 25 matrimonios sobre el número de hijos que tenían se obtuvieron los siguientes datos:
| 1 | 2 | 4 | 2 | 2 | 2 | 3 | 2 | 1 | 1 | 0 | 2 | 2 | 0 | 2 | 2 | 1 | 2 | 2 | 3 | 1 | 2 | 2 | 1 | 2 |
-
Crear un conjunto de datos con la variable
hijos.TipSolucióndf <- data.frame(hijos = c(1, 2, 4, 2, 2, 2, 3, 2, 1, 1, 0, 2, 2, 0, 2, 2, 1, 2, 2, 3, 1, 2, 2, 1, 2))Crear un data frame df con una columna llamada hijos que contenga los siguientes datos: 1, 2, 4, 2, 2, 2, 3, 2, 1, 1, 0, 2, 2, 0, 2, 2, 1, 2, 2, 3, 1, 2, 2, 1 y 2. -
Construir la tabla de frecuencias.
TipSoluciónPara obtener las frecuencias absolutas de una columna de un data frame se puede usar la siguiente función del paquete
basede R:-
table(vector). Devuelve una tabla con las frecuencias absolutas de cada valor delvectordado.
Para obtener las frecuencias relativas de una columna de un data frame se puede usar la siguiente función del paquete
basede R:-
prop.table(vector). Devuelve una tabla con las frecuencias relativas de cada valor del vector.
Posteriormente, para obtener las frecuencias acumuladas de una columna de un data frame se puede usar la siguiente función del paquete
basede R sobre las tablas de frecuencias absolutas y relativas obtenidas:-
cumsum(vector). Devuelve un vector con las frecuencias acumuladas de cada valor delvectordado.
library(knitr) # Frecuencias absolutas. ni <- table(df$hijos) # Frecuencias relativas fi <- prop.table(ni) # Frecuencias acumuladas. Ni <- cumsum(ni) # Frecuencias relativas acumuladas. Fi <- cumsum(fi) # Creamos un data frame con las frecuencias. tabla_frec <- cbind(ni, fi, Ni, Fi) kable(tabla_frec)ni fi Ni Fi 0 2 0.08 2 0.08 1 6 0.24 8 0.32 2 14 0.56 22 0.88 3 2 0.08 24 0.96 4 1 0.04 25 1.00 Para obtener la tabla de frecuencias de una columna de un data frame podemos usar la siguiente función del paquete
dplyrdetidyverse:-
count(df, columna). Devuelve un data frame con las frecuencias absolutas de cada valor de la columna especificada.
Posteriormente, para calcular el resto de frecuencias, podemos añadir nuevas columnas a la tabla de frecuencias mediante la siguiente función del paquete
dplyrdetidyverse:-
mutate(df, variable = formula). Añade una nueva columna al data frame usando lafórmuladada. Se deben usar las siguientes fórmulas para calcular las frecuencias relativas (n/sum(n)), frecuencias absolutas acumuladas (cumsum(n)) y frecuencias relativas acumuladas (cumsum(n)/sum(n)).
hijos ni fi Ni Fi 0 2 0.08 2 0.08 1 6 0.24 8 0.32 2 14 0.56 22 0.88 3 2 0.08 24 0.96 4 1 0.04 25 1.00 También podemos obtener la tabla de frecuencias usando las siguientes funciones del paquete
dplyrdetidyverse:group_by(df, columna). Agrupa el data frame según los valores de lacolumnaespecificada.[
summarise(df, variable = formula)](https://dplyr.tidyverse.org/reference/summarise.html). Devuelve un data frame con un resumen que se obtiene a partir del data frame df usando la fórmula indicada. Se deben usar las siguientes fórmulas para calcular las frecuencias absolutas (n()), frecuencias relativas (n()/nrow(df)), frecuencias absolutas acumuladas (cumsum(n())) y frecuencias relativas acumuladas (cumsum(n())/ nrow(df)`).
df |> # Agrupamos el data frame por la columna hijos. group_by(hijos) |> # Hacemos un resumen de cada grupo. summarise( # Frecuencias absolutas. ni = n(), # Frecuencias relativas. fi = n() / nrow(df), # Frecuencias absolutas acumuladas. Ni = cumsum(n()), # Frecuencias relativas acumuladas. Fi = cumsum(n()) / nrow(df) ) |> kable()hijos ni fi Ni Fi 0 2 0.08 2 0.08 1 6 0.24 6 0.24 2 14 0.56 14 0.56 3 2 0.08 2 0.08 4 1 0.04 1 0.04 Crear una tabla de frecuencias con las frecuencias absolutas (ni), relativas (fi), acumuladas (Ni) y relativas acumuladas (Fi) del número de hijos. -
-
Dibujar el diagrama de barras de las frecuencias absolutas, relativas, absolutas acumuladas y relativas acumuladas.
TipSoluciónPara dibujar un diagrama de barras podemos usar la función
barplotdel paquetegraphics.Parámetros:
-
height: vector con las alturas de las barras. -
col: color de las barras. -
main: título del gráfico. -
xlab: etiqueta del eje x. -
ylab: etiqueta del eje y.
# Diagrama de barras de frecuencias absolutas. barplot(ni, col = "steelblue", main = "Distribución del número de hijos", xlab = "Hijos", ylab = "Frecuencia absoluta")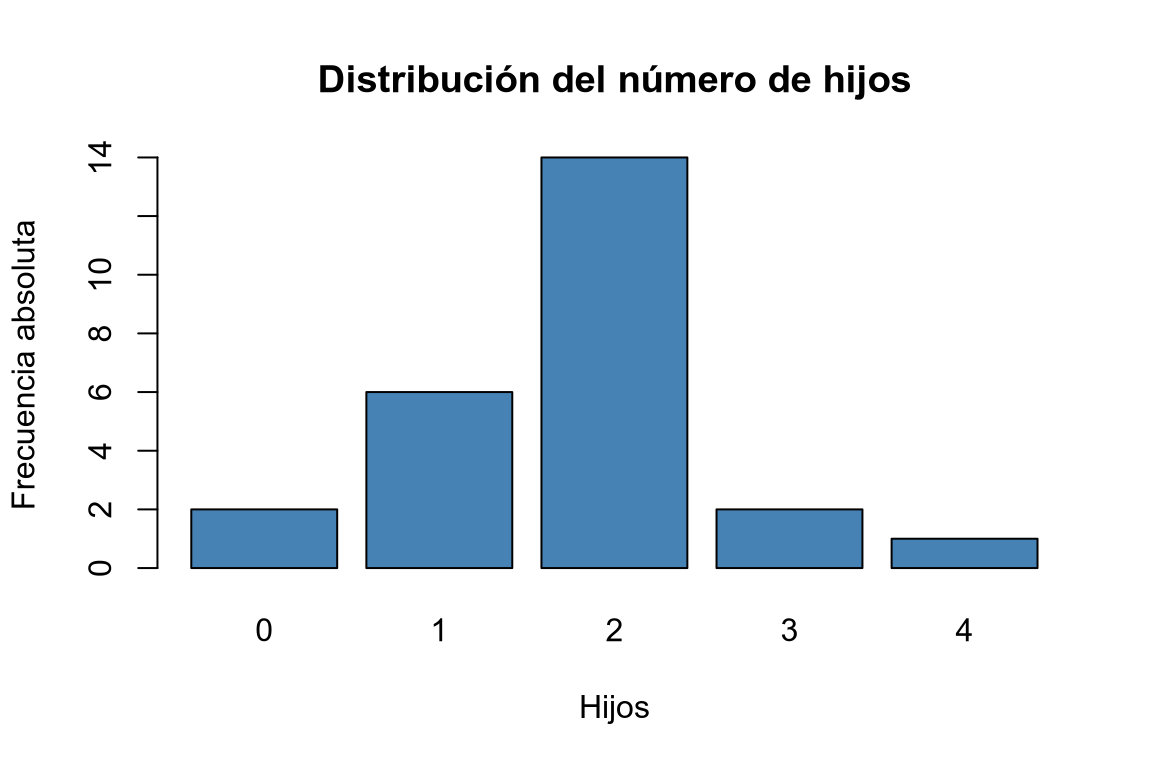
# Diagrama de barras de frecuencias relativas. barplot(fi, col = "steelblue", main = "Distribución del número de hijos", xlab = "Hijos", ylab = "Frecuencia relativa")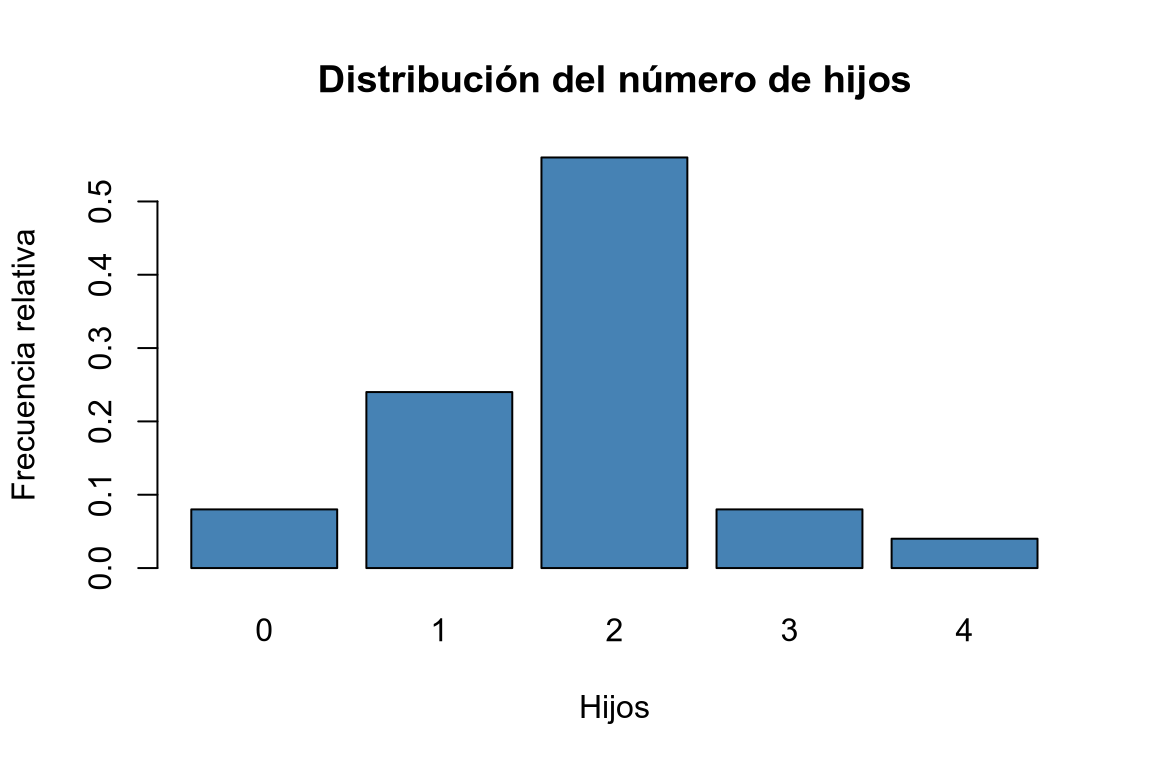
# Diagrama de barras de frecuencias absolutas acumuladas. barplot(Ni, col = "steelblue", main = "Distribución acumulada del número de hijos", xlab = "Hijos", ylab = "Frecuencia absoluta acumulada")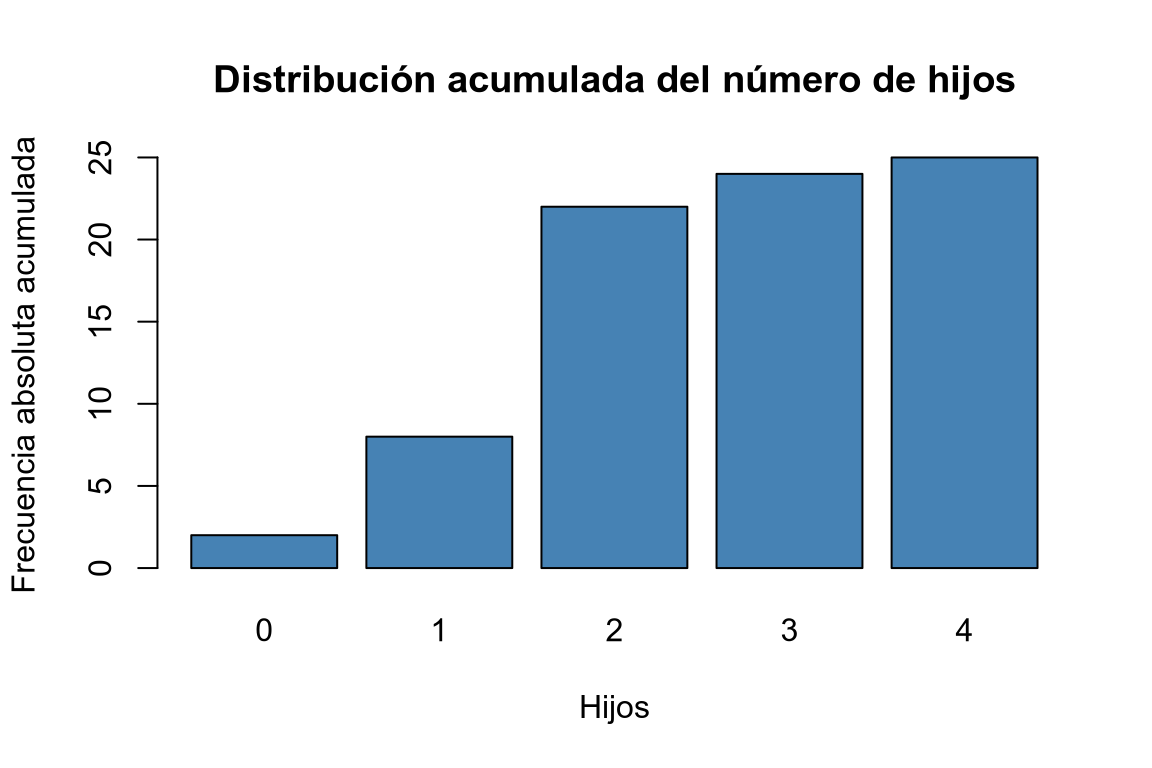
# Diagrama de barras de frecuencias relativas acumuladas. barplot(Fi, col = "steelblue", main = "Distribución acumulada del número de hijos", xlab = "Hijos", ylab = "Frecuencia relativa acumulada")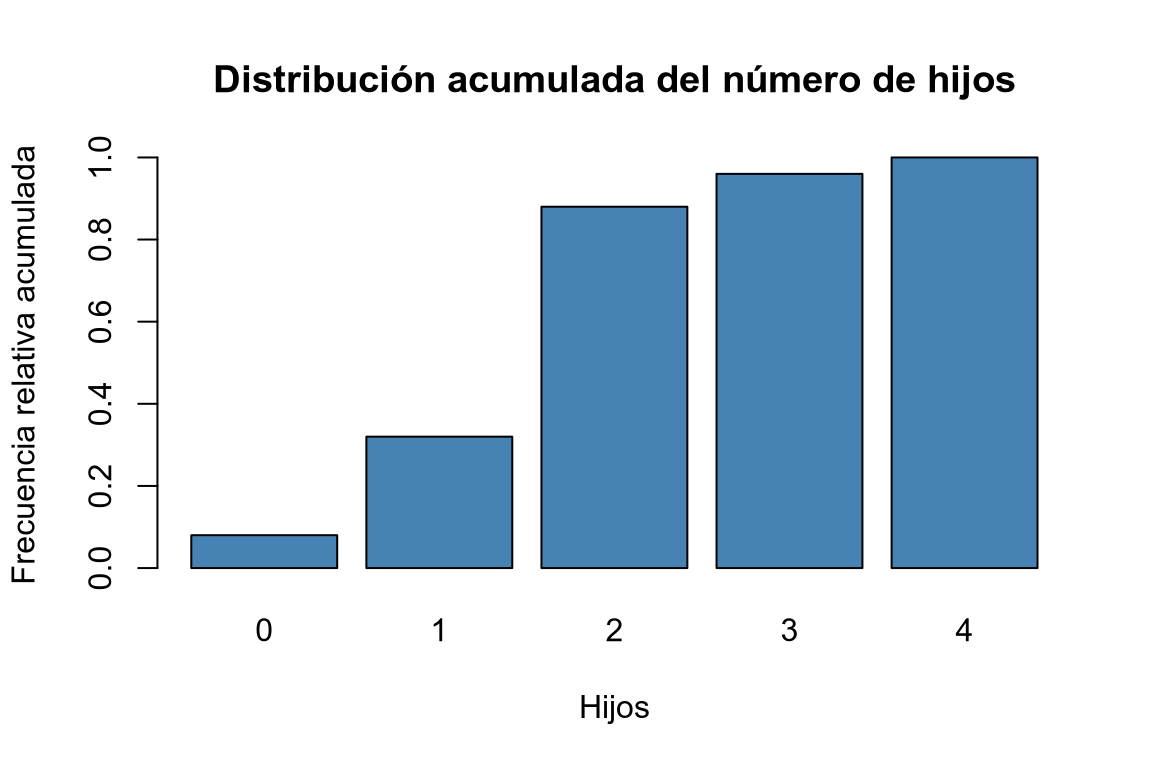
Para dibujar un diagrama de barras podemos usar la función
geom_bardel paqueteggplot2detidyverse. Esta función calcula automáticamente las frecuencias absolutas de la columna indicada en la dimensiónxpara barras horizontales oypara barras verticales.Parámetros:
- color: color del borde de las barras.
- fill: color de relleno de las barras.
- width: anchura de las barras (valor entre 0 y 1).
Para dibujar el diagrama de barras de frecuencias relativas o acumuladas, se le pude pasar como parámetro la función
after_stata la dimensióny:-
after_stat(count/sum(count)): para las frecuencias relativas. -
after_stat(cumsum(count)): para las frecuencias absolutas acumuladas. -
after_stat(cumsum(count)/sum(count)): para las frecuencias relativas acumuladas.
# Diagrama de barras de frecuencias absolutas # Añadimos la variable a la dimensión x. df |> ggplot(aes(x = hijos)) + # Añadimos la geometría de barras. geom_bar(fill = "steelblue") + # Añadimos el título y las etiquetas de los ejes. labs(title = "Distribución del número de hijos", y = "Frecuencia absoluta")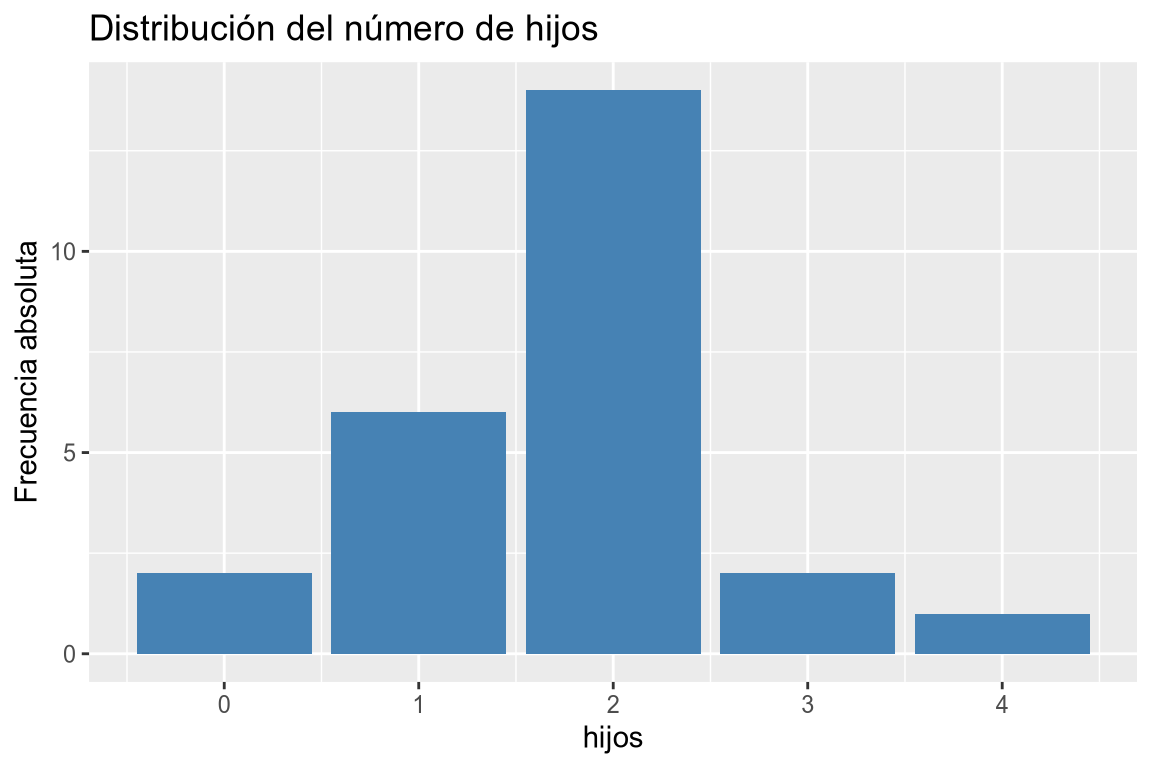
# Diagrama de barras de frecuencias relativas # Añadimos la variable a la dimensión x. df |> ggplot(aes(x = hijos)) + # Añadimos la geometría de barras y asignamos a la dimensión y las frecuencias relativas. geom_bar(aes(y = after_stat(count/sum(count))), fill = "steelblue") + # Añadimos el título y las etiquetas de los ejes. labs(title = "Distribución del número de hijos", y = "Frecuencia relativa")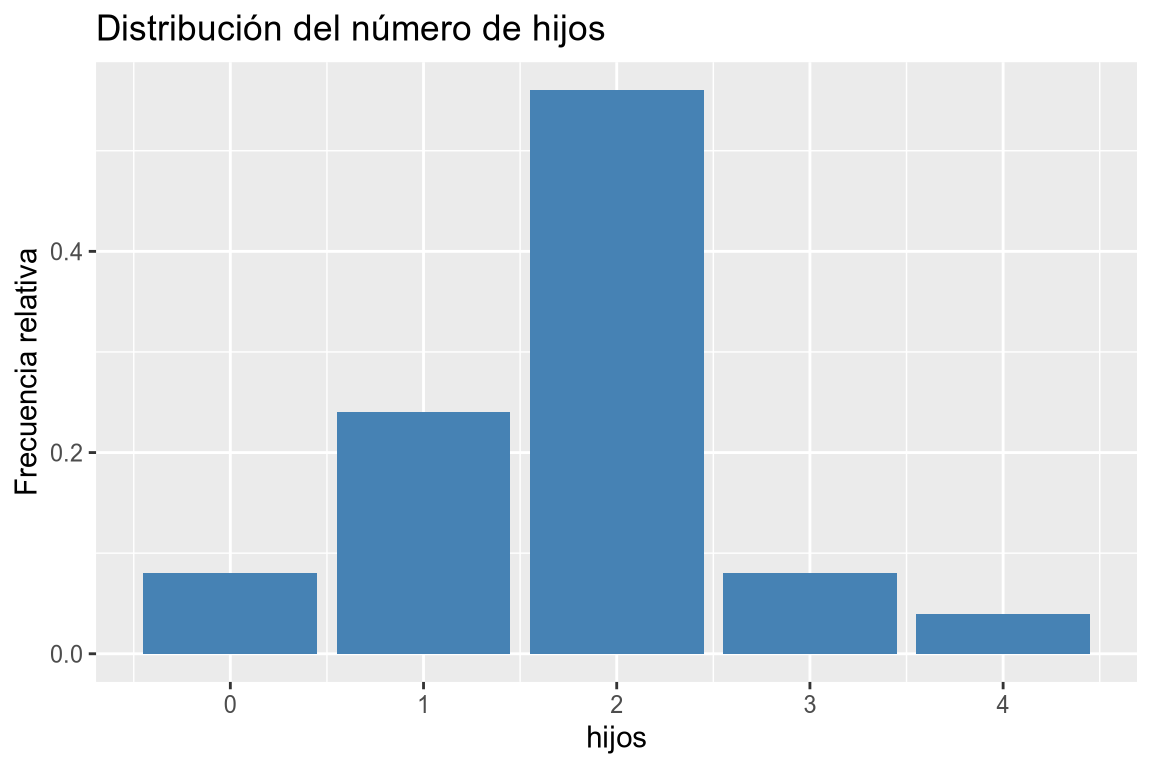
# Diagrama de barras de frecuencias acumuladas # Añadimos la variable a la dimensión x. df |> ggplot(aes(x = hijos)) + # Añadimos la geometría de barras y asignamos a la dimensión y las frecuencias absolutas acumuladas. geom_bar(aes(y = after_stat(cumsum(count))), fill = "steelblue") + # Añadimos el título y las etiquetas de los ejes. labs(title = "Distribución acumulada del número de hijos", y = "Frecuencia absoluta acumulada")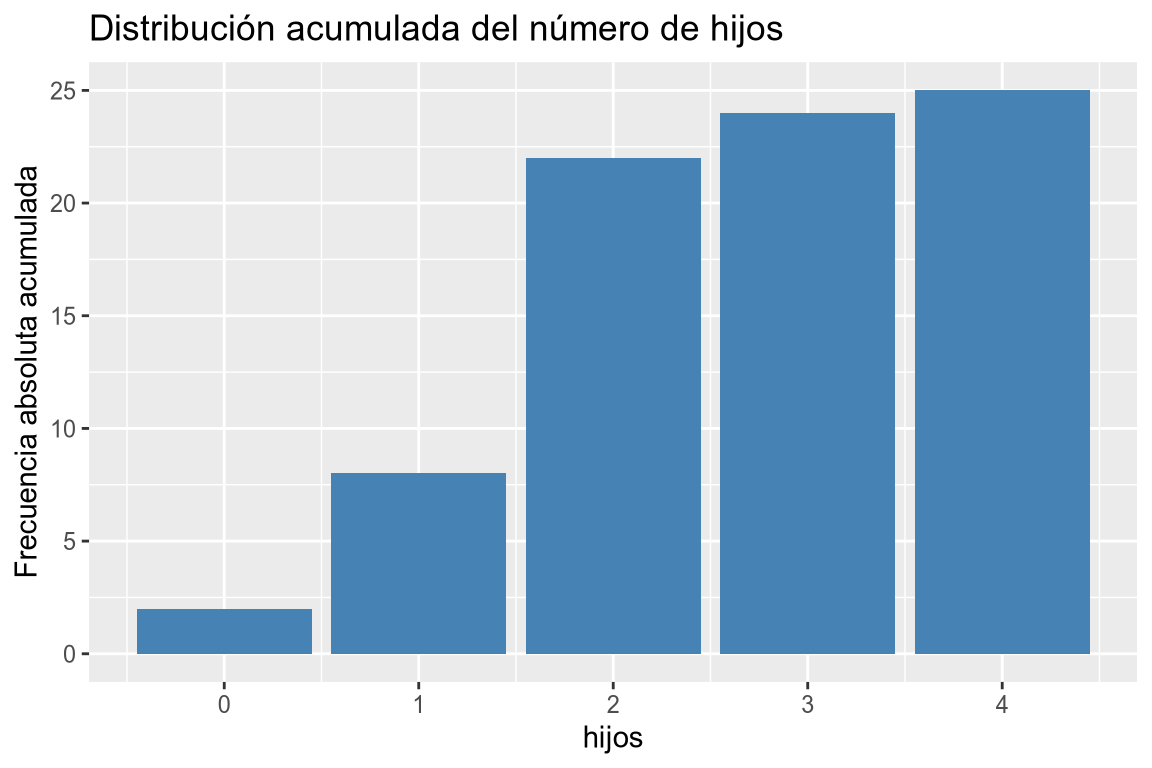
# Diagrama de barras de frecuencias acumuladas # Añadimos la variable a la dimensión x. df |> ggplot(aes(x = hijos)) + # Añadimos la geometría de barras y asignamos a la dimensión y las frecuencias relativas acumuladas. geom_bar(aes(y = after_stat(cumsum(count)/sum(count))), fill = "steelblue") + # Añadimos el título y las etiquetas de los ejes. labs(title = "Distribución acumulada del número de hijos", y = "Frecuencia relativa acumulada")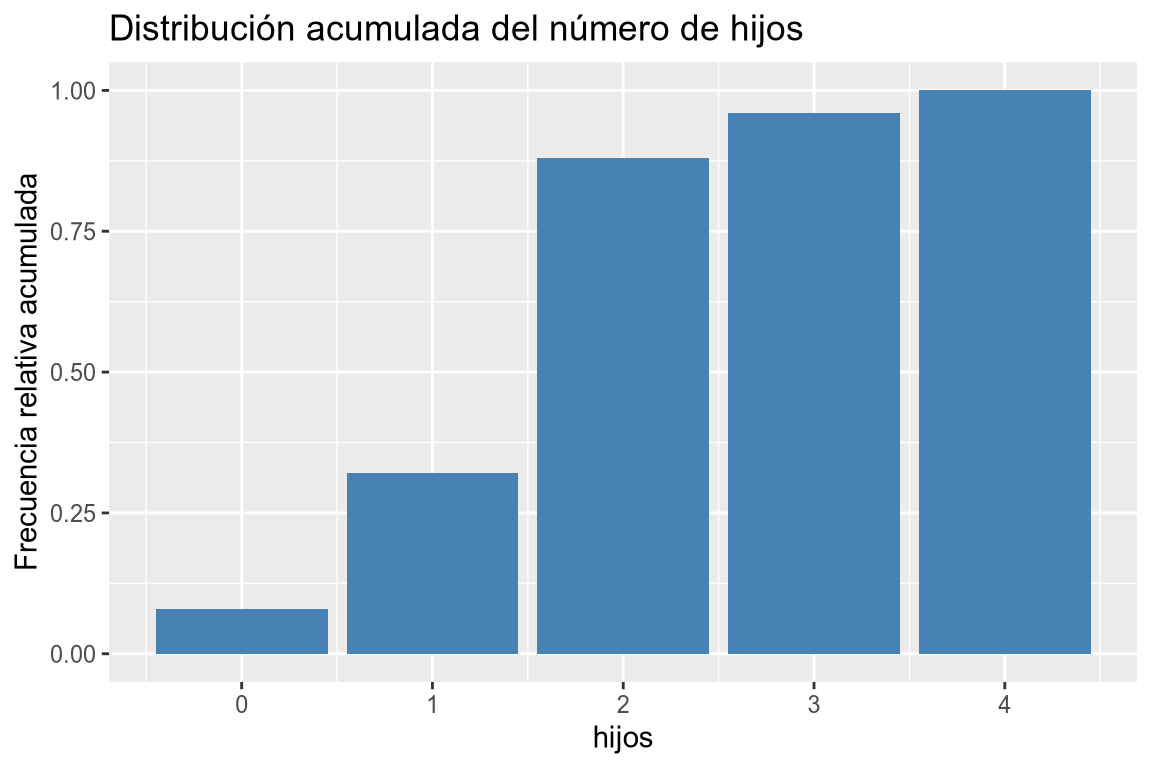
Dibujar un diagrama de barras con las frecuencias absolutas del número de hijos del data frame df. Dibujar un diagrama de barras con las frecuencias relativas del número de hijos del data frame df. Dibujar un diagrama de barras con las frecuencias absolutas acumuladas del número de hijos del data frame df. Dibujar un diagrama de barras con las frecuencias relativas acumuladas del número de hijos del data frame df. -
-
Dibujar el polígono de frecuencias relativas.
TipSoluciónPara dibujar el polígono de frecuencias podemos usar la función
plotdel paquetegraphics.Parámetros:
-
x: tabla con las frecuencias. -
type: tipo de gráfico. Para un polígono de frecuencias se usa"l"(línea). -
col: color de la línea. -
main: título del gráfico. -
xlab: etiqueta del eje x. -
ylab: etiqueta del eje y.
# Frecuencias relativas. plot(fi, type = "l", col = "steelblue", main = "Distribución del número de hijos", xlab = "Hijos", ylab = "Frecuencia relativa")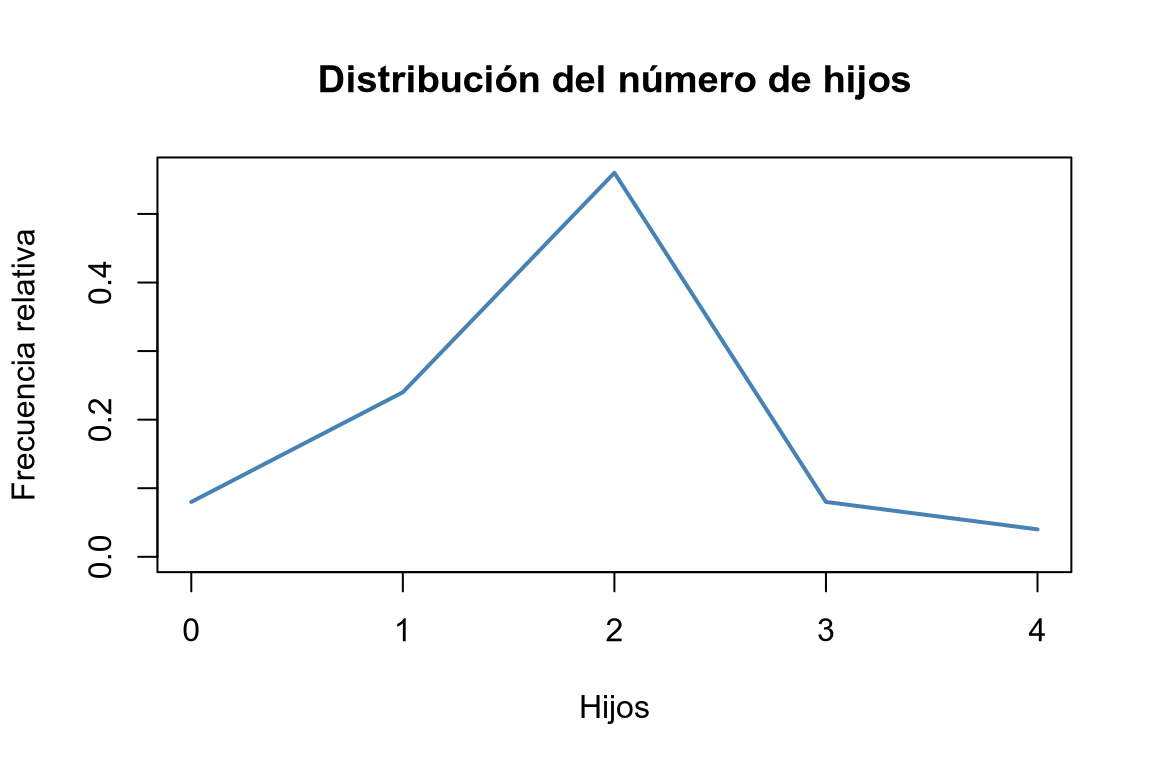
Par dibujar el polígono de frecuencias podemos usar la función
Parámetros:geom_linedel paqueteggplot2detidyverse, que conecta con segmentos los puntos con coordenadas pasadas en las dimensionesxey.-
col: color de la línea. -
size: grosor de la línea. -
linetype: tipo de línea (por ejemplo, “solid”, “dashed”, “dotted”).
# Calculamos las frecuencias absolutas. df |> count(hijos, name = "ni") |> # Añadimos una nueva columna con las frecuencias relativas. mutate(fi = ni/sum(ni)) |> # Añadimos los hijos a la dimensión x y las frecuencias relativas a la dimensión y. ggplot(aes(x = hijos, y = fi)) + # Añadimos la geometría de líneas. geom_line(col = "steelblue") + # Añadimos el título y las etiquetas de los ejes. labs(title = "Distribución del número de hijos", y = "Frecuencia relativa")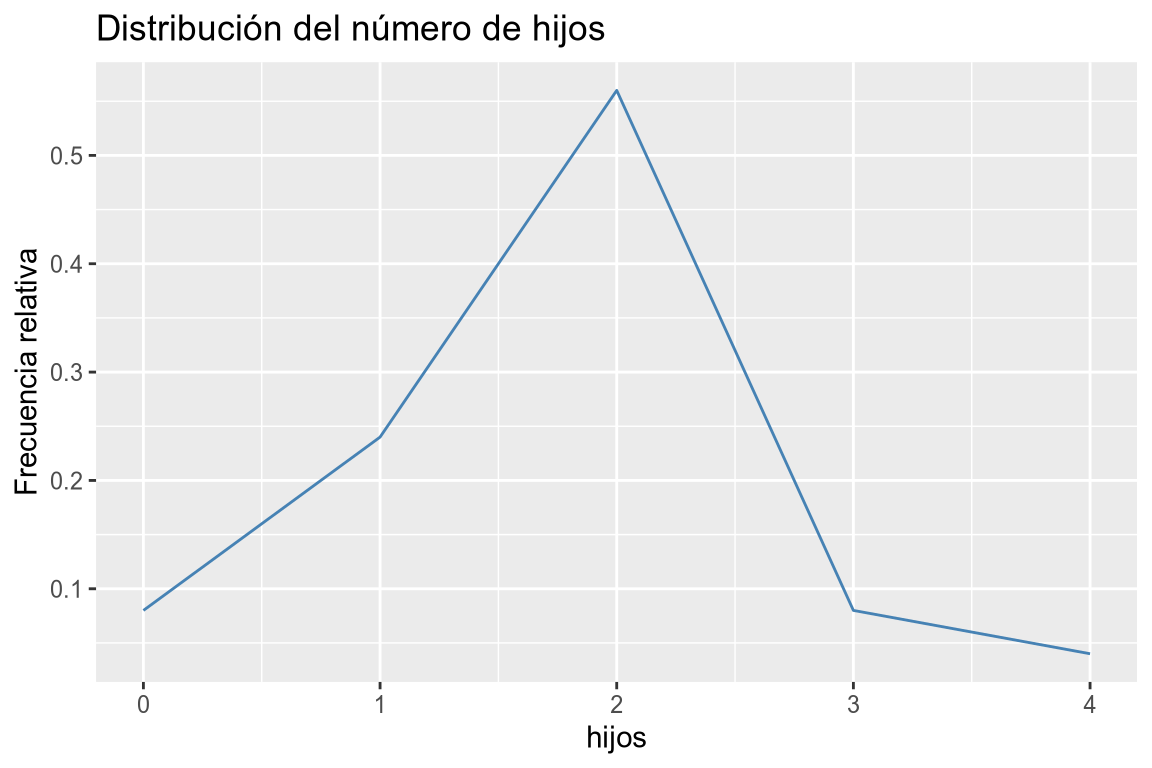
Dibujar un diagrama de líneas con las frecuencias absolutas del número de hijos del data frame df. Dibujar un diagrama de líneas con las frecuencias relativas del número de hijos del data frame df. Dibujar un diagrama de líneas con las frecuencias absolutas acumuladas del número de hijos del data frame df. Dibujar un diagrama de líneas con las frecuencias relativas acumuladas del número de hijos del data frame df. -
Ejercicio 4.2 En un hospital se realizó un estudio sobre el número de personas que ingresaron en urgencias cada día del mes de noviembre. Los datos observados fueron:
| 15 | 23 | 12 | 10 | 28 | 50 | 12 | 17 | 20 | 21 | 18 | 13 | 11 | 12 | 26 |
| 30 | 6 | 16 | 19 | 22 | 14 | 17 | 21 | 28 | 9 | 16 | 13 | 11 | 16 | 20 |
-
Crear un conjunto de datos con la variable
urgencias.TipSolucióndf <- data.frame(urgencias = c(15, 23, 12, 10, 28, 50, 12, 17, 20, 21, 18, 13, 11, 12, 26, 30, 6, 16, 19, 22, 14, 17, 21, 28, 9, 16, 13, 11, 16, 20))Crear un data frame df con una columna urgencias con los siguientes datos del número diario de personas atendidas en urgencias durante el mes de noviembre: 15, 23, 12, 10, 28, 50, 12, 17, 20, 21, 18, 13, 11, 12, 26, 30, 6, 16, 19, 22, 14, 17, 21, 28, 9, 16, 13, 11, 16 y 20. -
Dibujar el diagrama de cajas. ¿Existe algún dato atípico? En el caso de que exista, eliminarlo y proceder con los siguientes apartados.
TipSoluciónPara dibujar un diagrama de caja y bigotes podemos usar la función
boxplotdel paquetegraphics.Parámetros:
-
x: vector con las alturas de las barras. -
col: color de la caja. -
horizontal: orientación horizontal de la caja (True o False). -
width: anchura de la caja (valor entre 0 y 1). -
main: título del gráfico. -
xlab: etiqueta del eje x. -
ylab: etiqueta del eje y.
boxplot(df$urgencias, col = "steelblue", horizontal = T, main = "Distribución del número de urgencias", xlab = "Número de urgencias")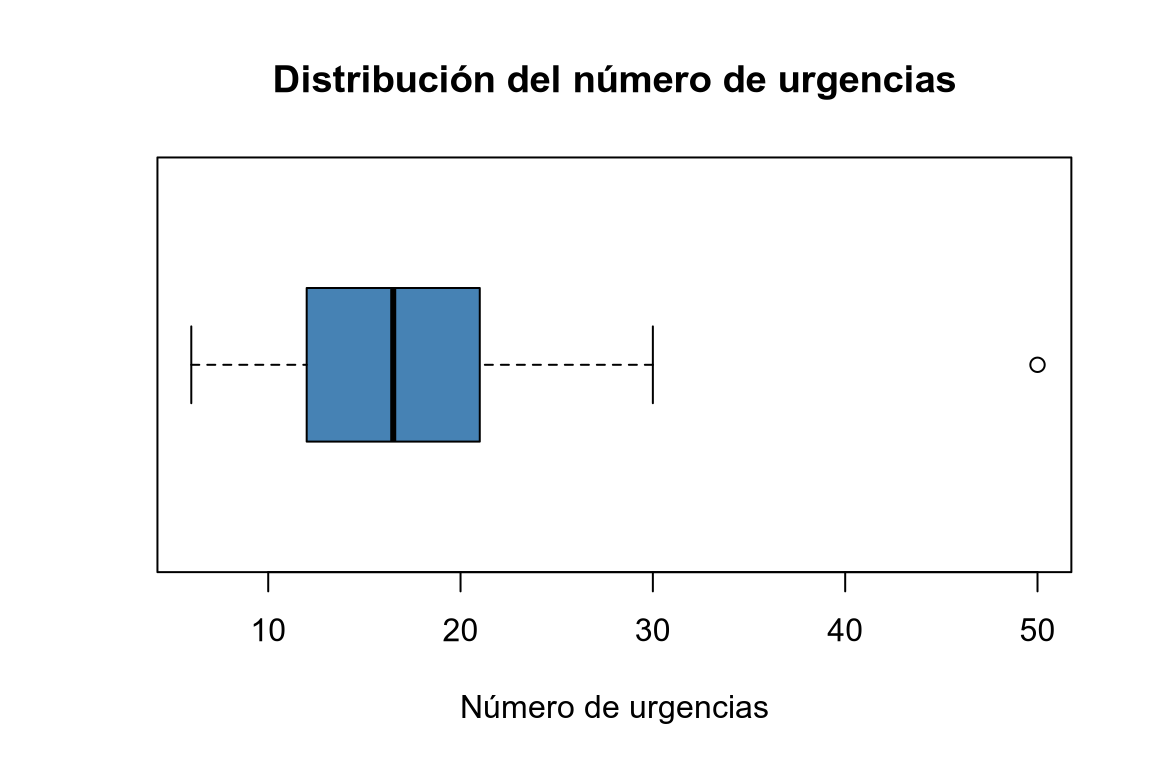
Para dibujar un diagrama de caja y bigotes podemos usar la función
geom_boxplotdel paqueteggplot2detidyverse.Parámetros:
- color: color del borde de la caja.
- fill: color de relleno de la caja.
- width: anchura de la caja.
# Añadimos la variable a la dimensión x. df |> ggplot(aes(x = urgencias)) + # Añadimos la geometría de cajas. geom_boxplot(fill = "steelblue") + # Eliminamos las marcas del eje y. scale_y_continuous(breaks = NULL) + # Añadimos el título y las etiquetas. labs(title = "Distribución del número de urgencias", x = "Número de urgencias")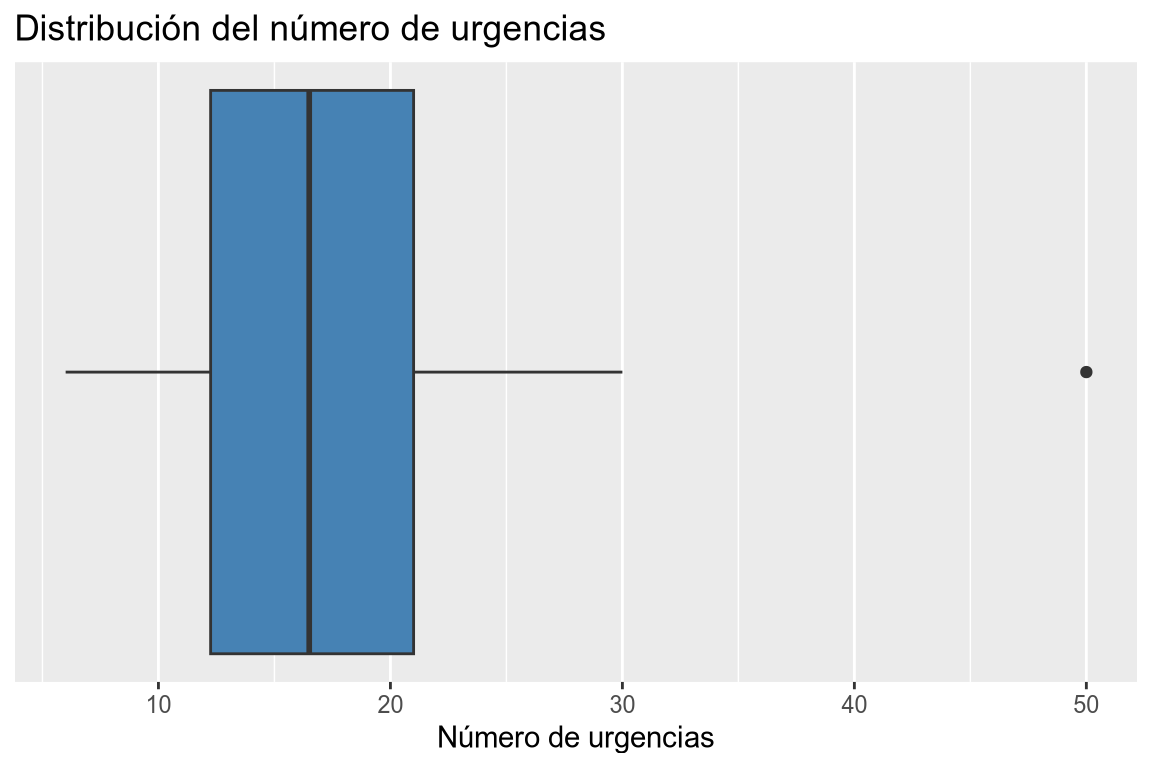
Dibujar un diagrama de cajas con la columna urgencias del data frame df.Hay un día con 50 urgencias, que es un valor atípico en comparación con el resto de días.
Podemos eliminar el dato atípico aplicando un filtro con la condición
df$urgencias != 50.# Eliminamos el dato atípico. df <- df[df$urgencias != 50, , drop = F]Podemos eliminar el dato atípico aplicando un filtro con la función
filterdel paquetedplyrdetidyversey la condiciónurgencias != 50.# Eliminamos el dato atípico. df <- filter(df, urgencias != 50)Eliminar el dato atípico de la columna urgencias del data frame df. -
-
Construir la tabla de frecuencias agrupando en 5 clases.
TipSoluciónPara agrupar los datos en intervalos se puede utilizar la función
cutdel paquete base de R.Parámetros:
-
breaks: número de intervalos o un vector con los puntos de corte de los intervalos.
Para contar las frecuencias absolutas y relativas podemos usar las funciones
table, yprop.tablerespectivamente.Posteriormente, para obtener las frecuencias acumuladas se puede usar la función
cumsumaplicada a las frecuencias absolutas y relativas.library(knitr) # Calculamos las frecuencias absolutas agrupando en 5 clases desde 5 hasta 30. ni <- table(cut(df$urgencias, breaks = seq(5, 30, 5))) # Frecuencias relativas fi <- prop.table(ni) # Frecuencias acumuladas. Ni <- cumsum(ni) # Frecuencias relativas acumuladas. Fi <- cumsum(fi) # Creación de un data frame con las frecuencias. tabla_frec <- cbind(ni, fi, Ni, Fi) kable(tabla_frec)ni fi Ni Fi (5,10] 3 0.1034483 3 0.1034483 (10,15] 9 0.3103448 12 0.4137931 (15,20] 9 0.3103448 21 0.7241379 (20,25] 4 0.1379310 25 0.8620690 (25,30] 4 0.1379310 29 1.0000000 Para agrupar los datos en intervalos se puede utilizar la función
cutdel paquete base de R y añadir una nueva columna al data frame con la clase a la que pertenece cada individuo con la funciónmutate.Después, podemos obtener la tabla de frecuencias podemos usar la función
countdel paquetedplyrdetidyverse.Posteriormente podemos añadir nuevas columnas a la tabla de frecuencias mediante la función
mutatey fórmulas para calcular las frecuencias relativas (n/sum(n)), frecuencias absolutas acumuladas (cumsum(n)) y frecuencias relativas acumuladas (cumsum(n)/sum(n)).library(knitr) # Añadimos una nueva columna al data frame con la clase a la que pertenece cada individuo. df |> mutate(urgencias_int = cut(urgencias, breaks = seq(5, 30, 5))) |> # Calculamos la tabla de frecuencias absolutas. count(urgencias_int, name = "ni") |> # Añadimos nuevas columnas con la frecuencia relativa, acumulada y relativa acumulada. mutate(fi = ni/sum(ni), Ni = cumsum(ni), Fi = cumsum(ni)/sum(ni)) |> kable()urgencias_int ni fi Ni Fi (5,10] 3 0.1034483 3 0.1034483 (10,15] 9 0.3103448 12 0.4137931 (15,20] 9 0.3103448 21 0.7241379 (20,25] 4 0.1379310 25 0.8620690 (25,30] 4 0.1379310 29 1.0000000 Crear una tabla de frecuencias con las frecuencias absolutas (ni), relativas (fi), acumuladas (Ni) y relativas acumuladas (Fi) del número de urgencias agrupando en 5 clases desde 5 hasta 30 mediante la función cut. -
-
Dibujar el histograma de frecuencias absolutas, relativas, absolutas acumuladas y relativas acumuladas correspondiente a la tabla anterior.
TipSoluciónPara dibujar un histograma de frecuencias absolutas podemos usar la función
histdel paquetegraphics.Parámetros:
-
breaks: Un vector con los puntos de corte de los intervalos de las barras. -
col: color de las barras. -
main: título del gráfico. -
xlab: etiqueta del eje x. -
ylab: etiqueta del eje y.
Después se puede cambiar el campo
countsdel histograma para indicar la altura de las barras. Para volver a dibujar el histograma, una vez modificadas las alturas de las barras, se tiene que utilizar la funciónplotdel paquetegraphics.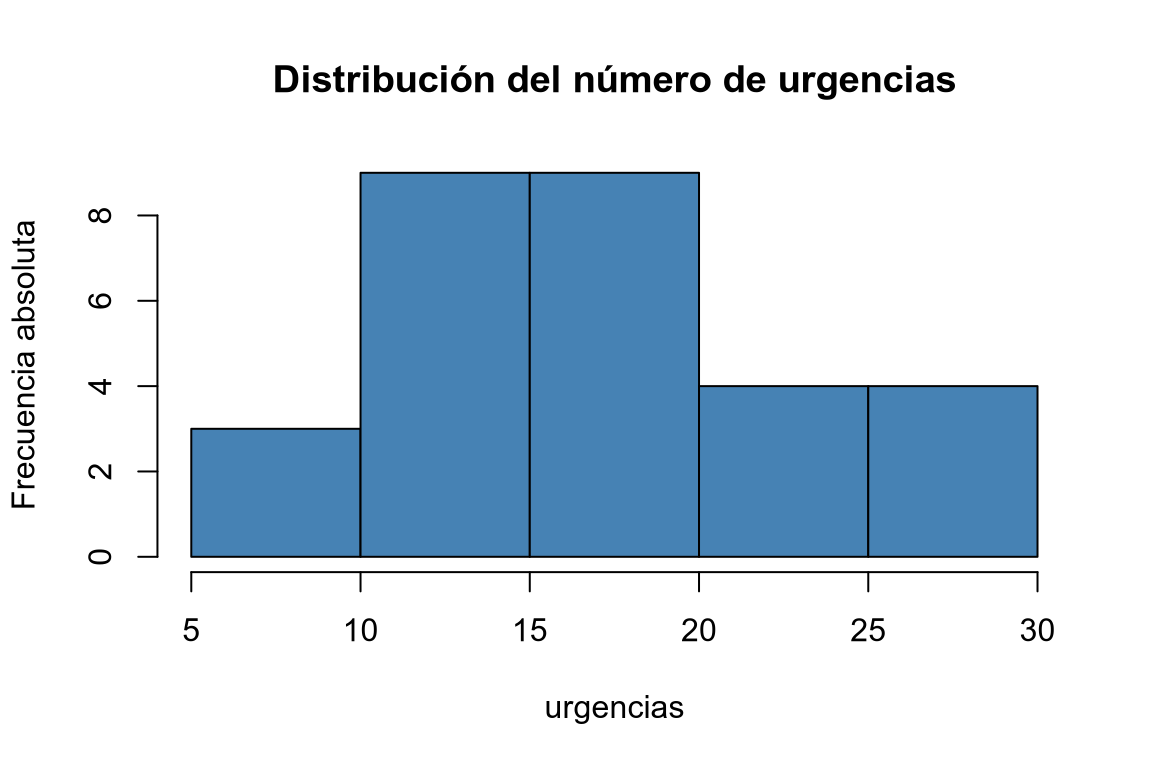
ni <- histo$counts # Histograma de frecuencias relativas. # Modificamos el campo counts del histograma para que contenga las frecuencias relativas. histo$counts <- ni/sum(ni) plot(histo, col = "steelblue", main = "Distribución del número de urgencias", xlab = "urgencias", ylab = "Frecuencia relativa")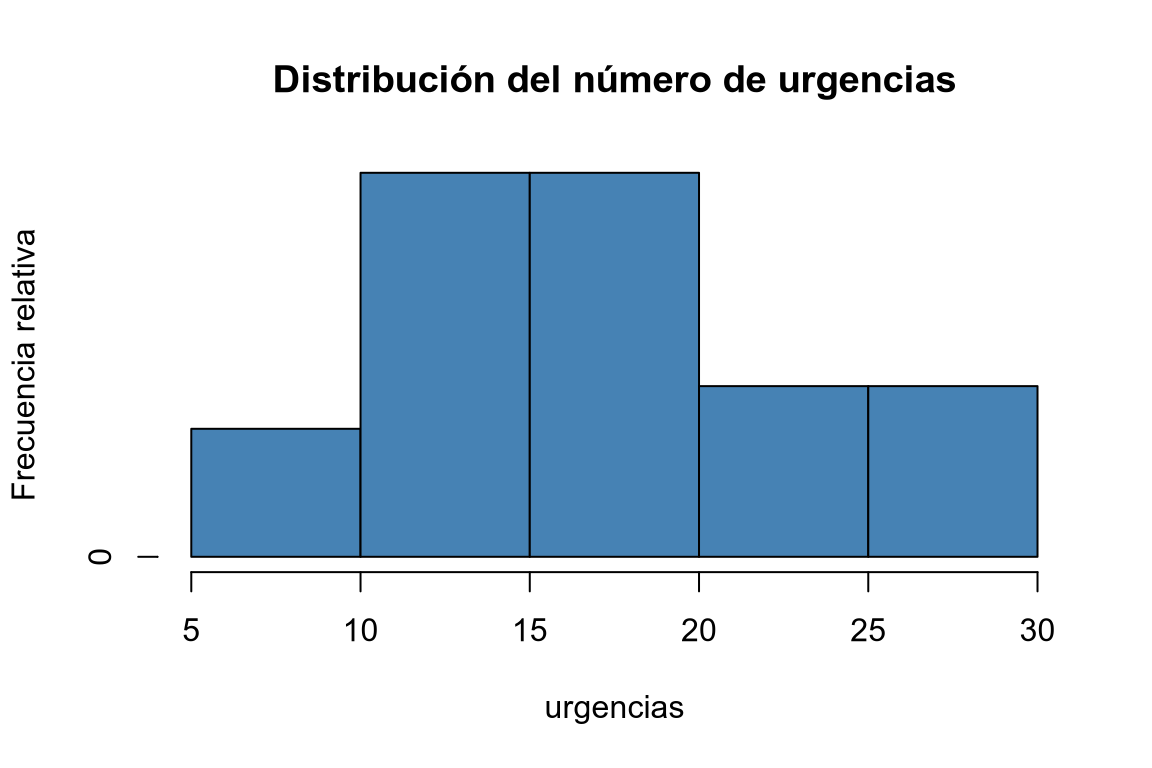
# Histograma de frecuencias absolutas acumuladas. # Modificamos el campo counts del histograma para que contenga las frecuencias absolutas acumuladas. histo$counts <- cumsum(ni) plot(histo, col = "steelblue", main = "Distribución acumulada del número de urgencias", xlab = "urgencias", ylab = "Frecuencia absoluta acumulada")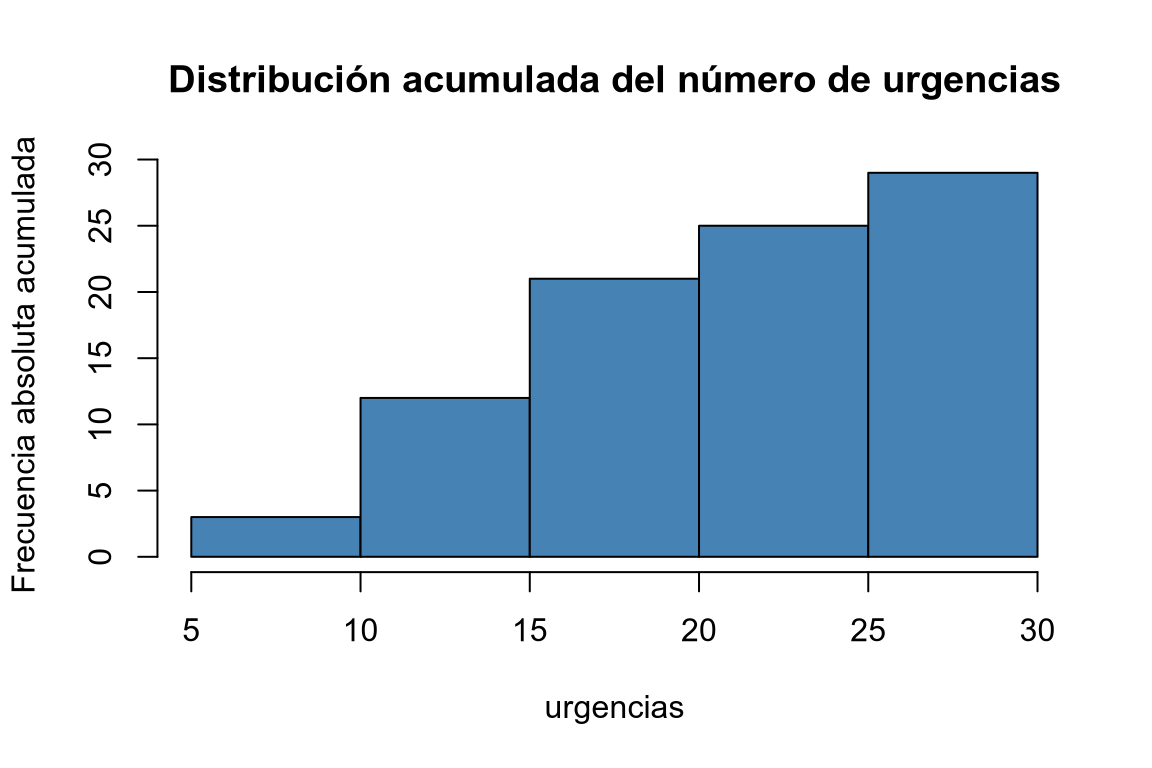
# Histograma de frecuencias relativas acumuladas. # Modificamos el campo counts del histograma para que contenga las frecuencias relativas. histo$counts <- cumsum(ni)/sum(ni) plot(histo, col = "steelblue", main = "Distribución acumulada del número de urgencias", xlab = "urgencias", ylab = "Frecuencia relativa acumulada", )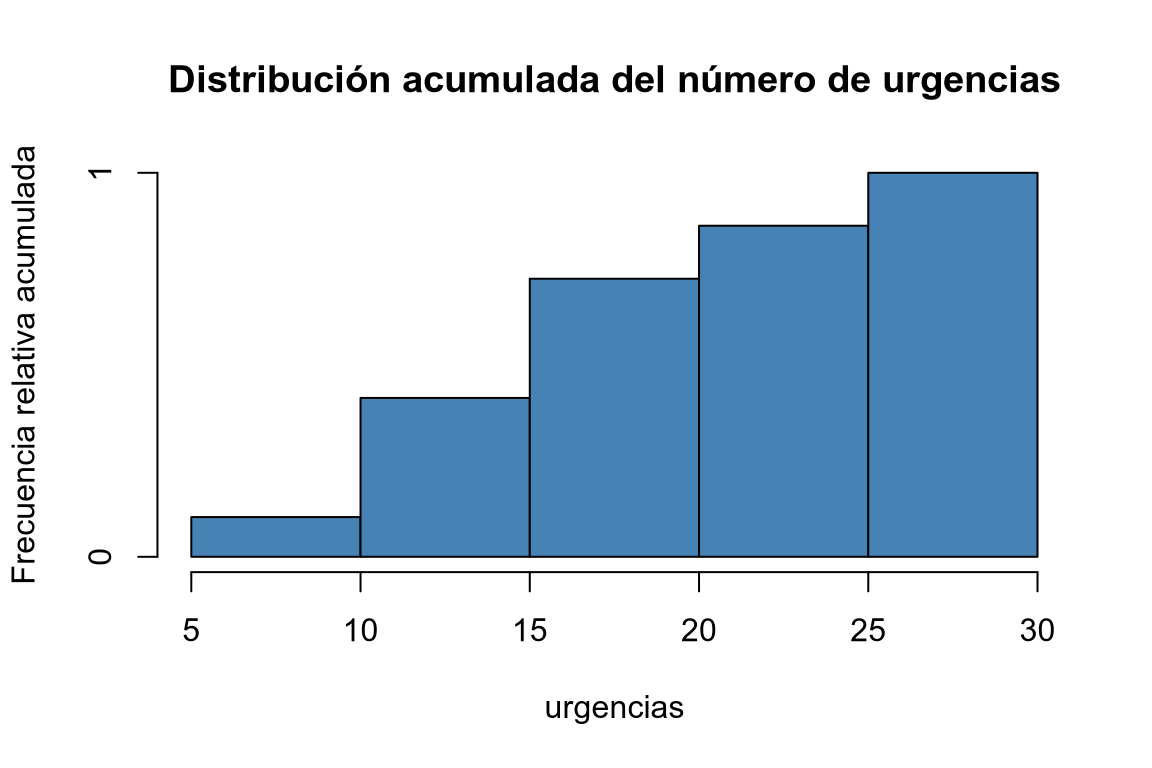
Para dibujar un histograma podemos usar la función
geom_histogramdel paqueteggplot2detidyverse.Parámetros:
-
breaks: Un vector con los puntos de corte de los intervalos de las barras. -
color: Color del borde de las barras. -
fill: Color de relleno de las barras.
Para dibujar el histograma de frecuencias relativas o acumuladas, se le pude pasar como parámetro la función
after_stata la dimesióny.-
after_stat(count/sum(count)): para las frecuencias relativas. -
after_stat(cumsum(count)): para las frecuencias absolutas acumuladas. -
after_stat(cumsum(count)/sum(count)): para las frecuencias relativas acumuladas.
# Histograma de frecuencias absolutas # Añadimos la variable a la dimensión x. df |> ggplot(aes(x = urgencias)) + # Añadimos la geometría de histograma creando clases de amplitud 5 desde 5 hasta 30. geom_histogram(breaks = seq(5, 30, 5), fill = "steelblue", col = "white") + # Añadimos el título y las etiquetas de los ejes. labs(title = "Distribución del número de urgencias", x = "Número de urgencias", y = "Frecuencia absoluta")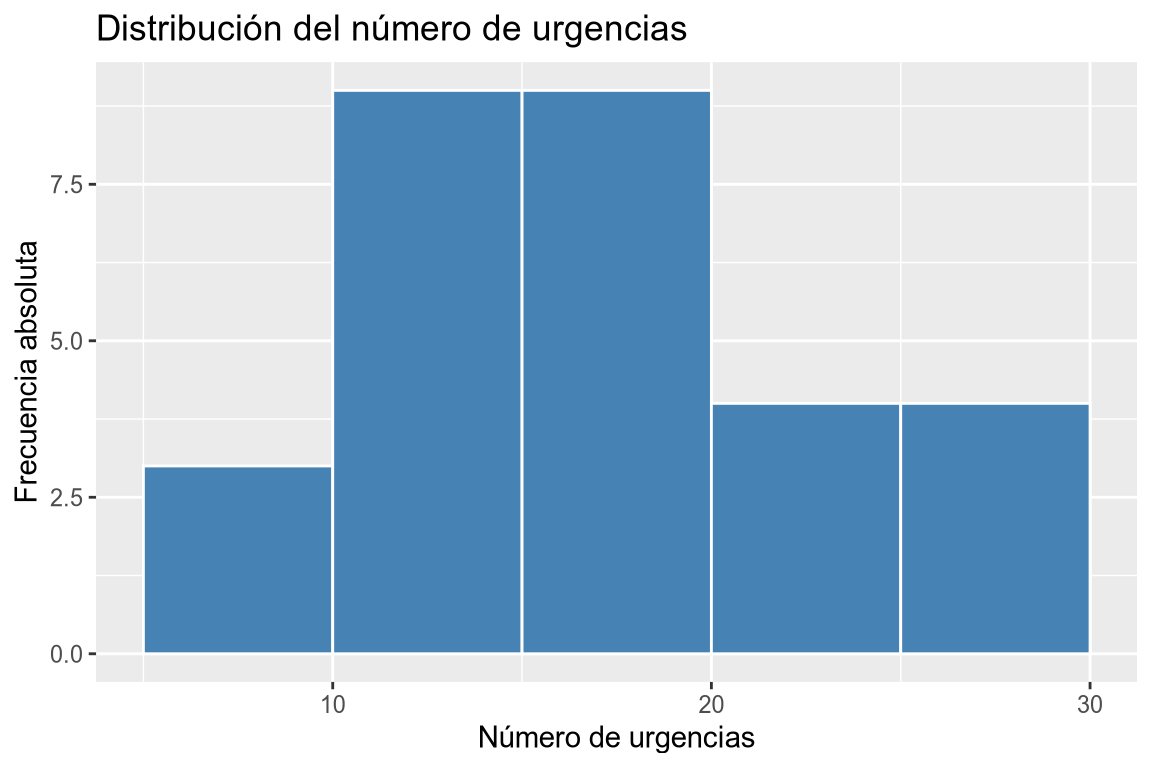
# Histograma de frecuencias relativas # Añadimos la variable a la dimensión x. df |> ggplot(aes(x = urgencias)) + # Añadimos la geometría de histograma y asignamos a la dimensión y las frecuencias relativas. geom_histogram(aes(y = after_stat(count/sum(count))), breaks = seq(5, 30, 5), fill = "steelblue", col = "white") + # Añadimos el título y las etiquetas de los ejes. labs(title = "Distribución del número de urgencias", x = "Número de urgencias", y = "Frecuencia relativa")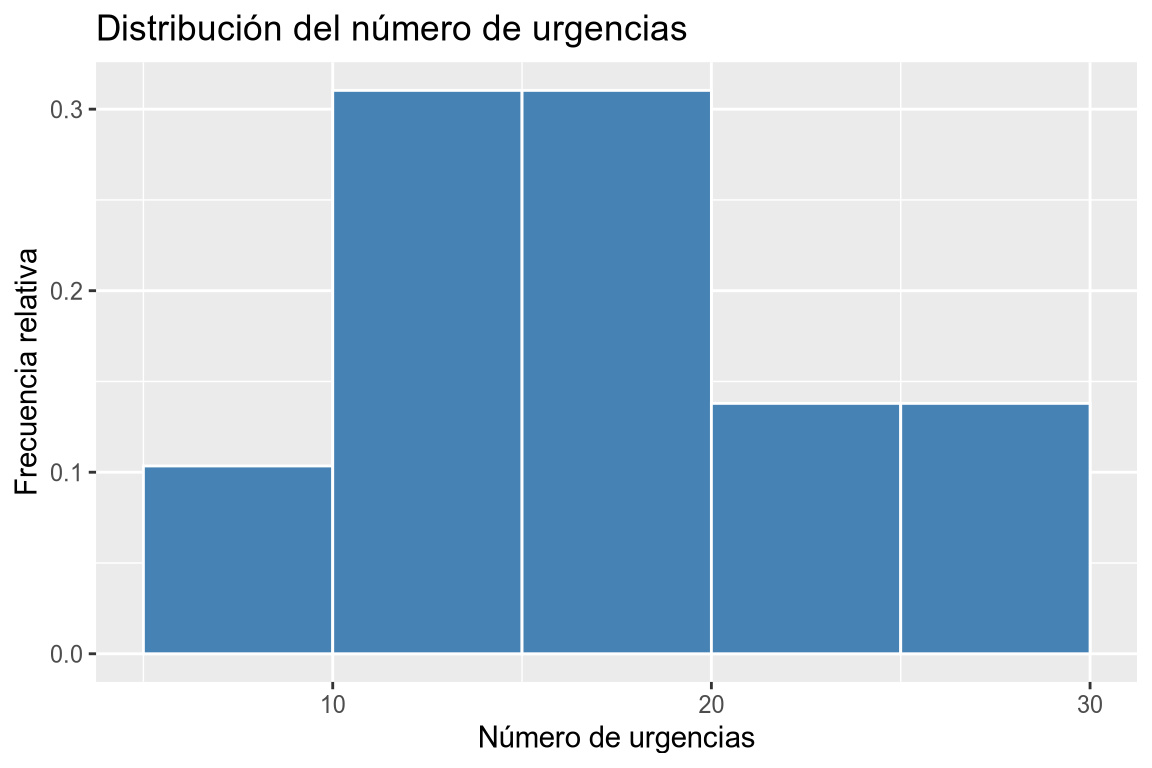
# Histograma de frecuencias acumuladas # Añadimos la variable a la dimensión x. df |> ggplot(aes(x = urgencias)) + # Añadimos la geometría de histograma y asignamos a la dimensión y las frecuencias absolutas acumuladas. geom_histogram(aes(y = after_stat(cumsum(count))), breaks = seq(5, 30, 5), fill = "steelblue", col = "white") + # Añadimos el título y las etiquetas de los ejes. labs(title = "Distribución acumulada del número de urgencias", x = "Número de urgencias", y = "Frecuencia absoluta acumulada")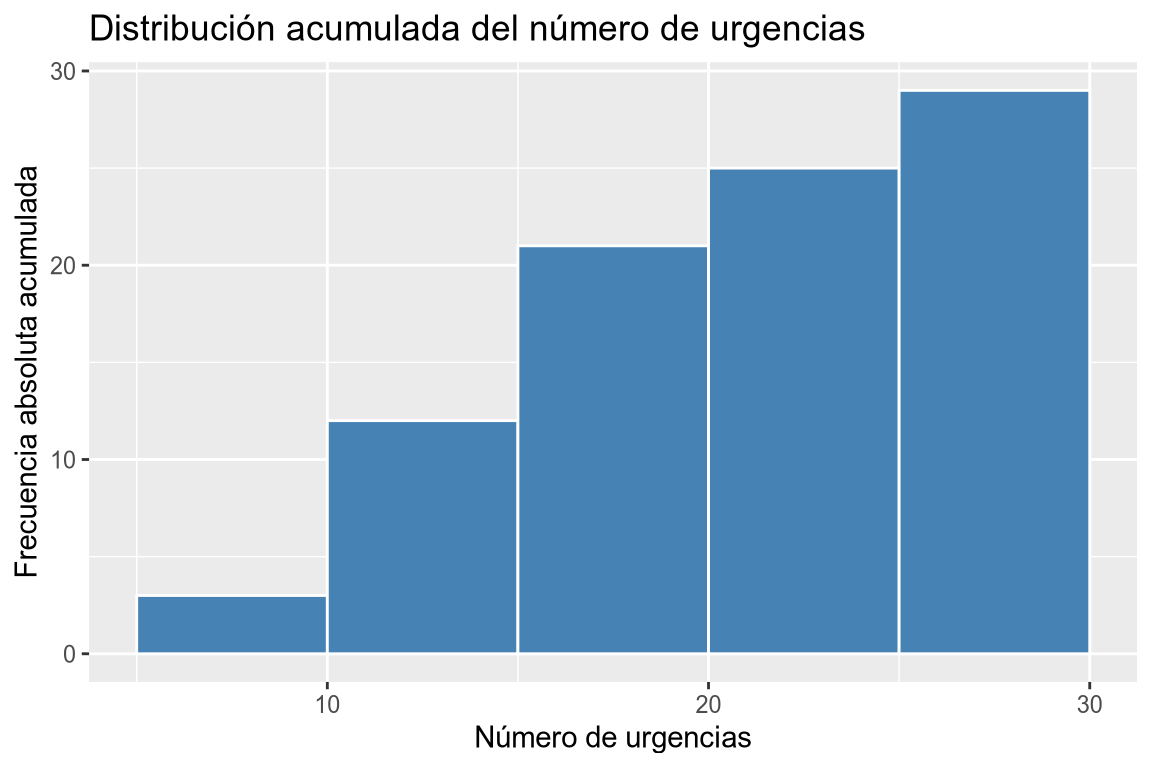
# Histograma de frecuencias relativas acumuladas # Añadimos la variable a la dimensión x. df |> ggplot(aes(x = urgencias)) + # Añadimos la geometría de histograma y asignamos a la dimensión y las frecuencias relativas acumuladas. geom_histogram(aes(y = after_stat(cumsum(count)/sum(count))), breaks = seq(5, 30, 5), fill = "steelblue", col = "white") + labs(title = "Distribución acumulada del número de urgencias", x = "Número de urgencias", y = "Frecuencia relativa acumulada")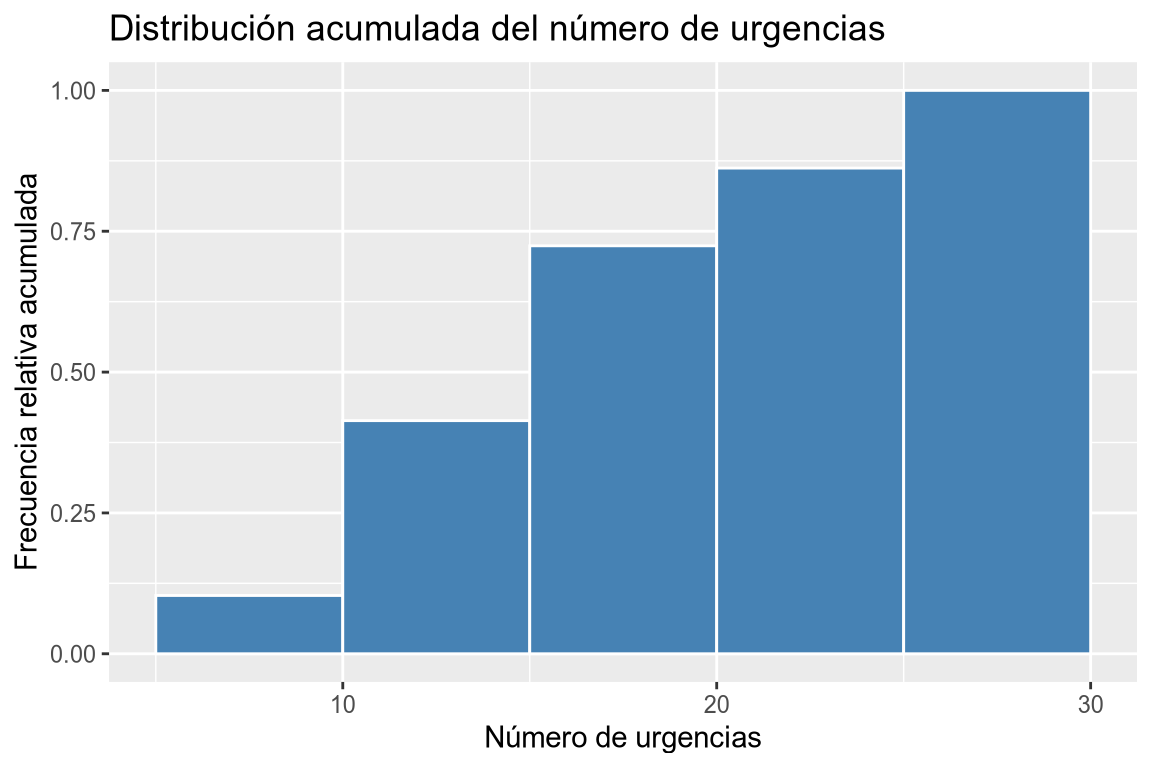
Dibujar un histograma con las frecuencias absolutas de la columna urgencias del data frame df agrupando en 5 clases desde 5 hasta 30. Dibujar un histograma con las frecuencias relativas de la columna urgencias del data frame df agrupando en 5 clases desde 5 hasta 30. Dibujar un histograma con las frecuencias absolutas acumuladas de la columna urgencias del data frame df agrupando en 5 clases desde 5 hasta 30. Dibujar un histograma con las frecuencias relativas acumuladas de la columna urgencias del data frame df agrupando en 5 clases desde 5 hasta 30. -
-
Dibujar el polígono de frecuencias relativas acumuladas (ojiva).
TipSoluciónPara dibujar el polígono de frecuencias relativas acumuladas podemos usar la función
plotdel paquetegraphics.Parámetros:
-
x: vector con las coordenadas x de los vértices del polígono. -
y: vector con las coordenadas y de los vértices del polígono. -
type: tipo de gráfico. Para un polígono de frecuencias se usa"l"(línea). -
col: color de la línea. -
main: título del gráfico. -
xlab: etiqueta del eje x. -
ylab: etiqueta del eje y.
# Ojiva # Definimos los puntos de corte de los intervalos. cortes = seq(5, 30, 5) # Calculamos las frecuencias absolutas agrupando en 5 clases. ni <- table(cut(df$urgencias, breaks = cortes)) # Calculamos las frecuencias relativas acumuladas. Fi <- c(0, cumsum(ni)/sum(ni)) # Dibujamos el polígono de frecuencias relativas acumuladas. plot(cortes, Fi, type = "l", col = "steelblue", main = "Distribución acumulada del número de urgencias", xlab = "Número de urgencias", ylab = "Frecuencia relativa acumulada")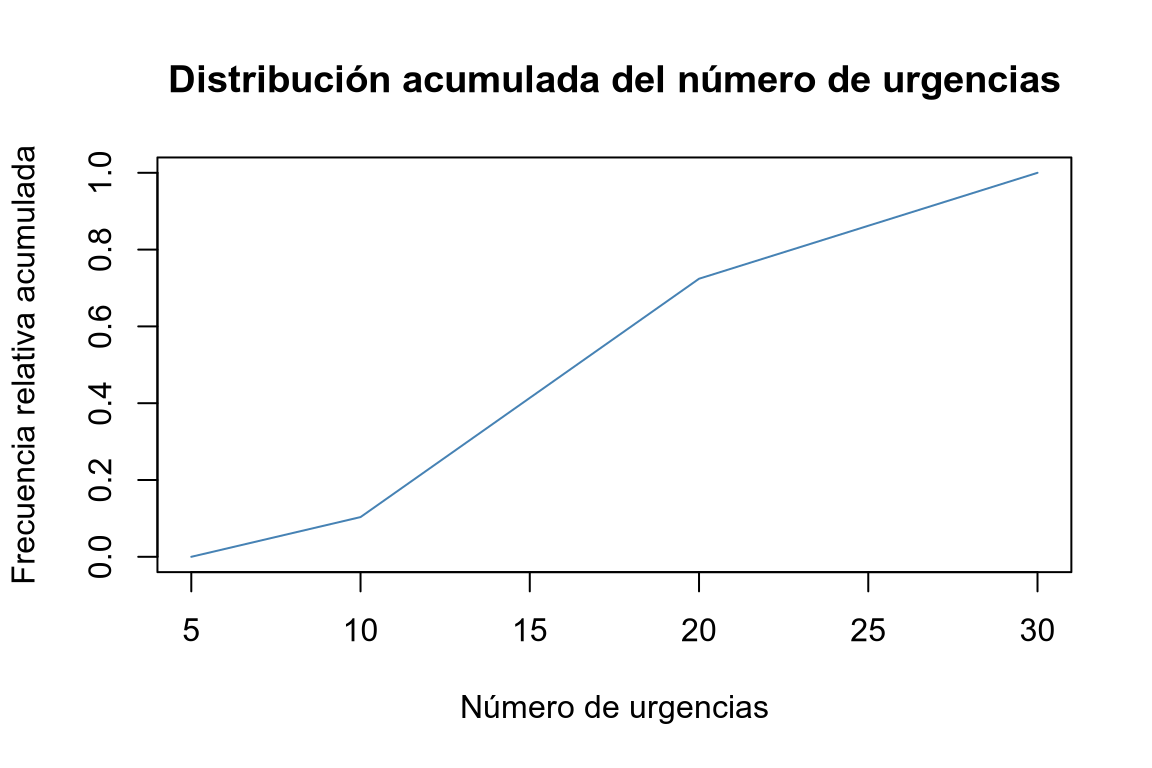
Para dibujar el polígono de frecuencias relativas acumuladas podemos usar la función
geom_linedel paqueteggplot2detidyverse.# Ojiva # Definimos los puntos de corte de los intervalos. cortes <- seq(5, 30, 5) # Añadimos una nueva columna al data frame con la clase a la que pertenece cada individuo, tomando 5 intervalos desde 5 hasta 30. tabla_frec <- df |> mutate(urgencias_int = cut(df$urgencias, breaks = cortes)) |> # Calculamos las frecuencias absolutas de cada clase. count(urgencias_int, name = "ni") |> # Añadimos una nueva columna con las frecuencias relativas acumuladas. mutate(cortes = cortes[-1], Fi = cumsum(ni)/sum(ni)) |> # Seleccionamos las columnas que nos interesan. select(cortes, Fi) # Añadimos una fila con el primer punto de corte y frecuencia relativa acumulada 0. tabla_frec <- rbind(data.frame(cortes = cortes[1], Fi = 0), tabla_frec) # Dibujamos el polígono de frecuencias relativas acumuladas. # Añadimos los cortes a la dimensión x y las frecuencias relativas acumuladas a ggplot(tabla_frec, aes(x = cortes , y = Fi)) + # Añadimos la geometría de líneas. geom_line(col = "steelblue") + # Añadimos el título y las etiquetas de los ejes. labs(title = "Distribución del número de urgencias", x = "Número de urgencias", y = "Frecuencia relativa acumulada")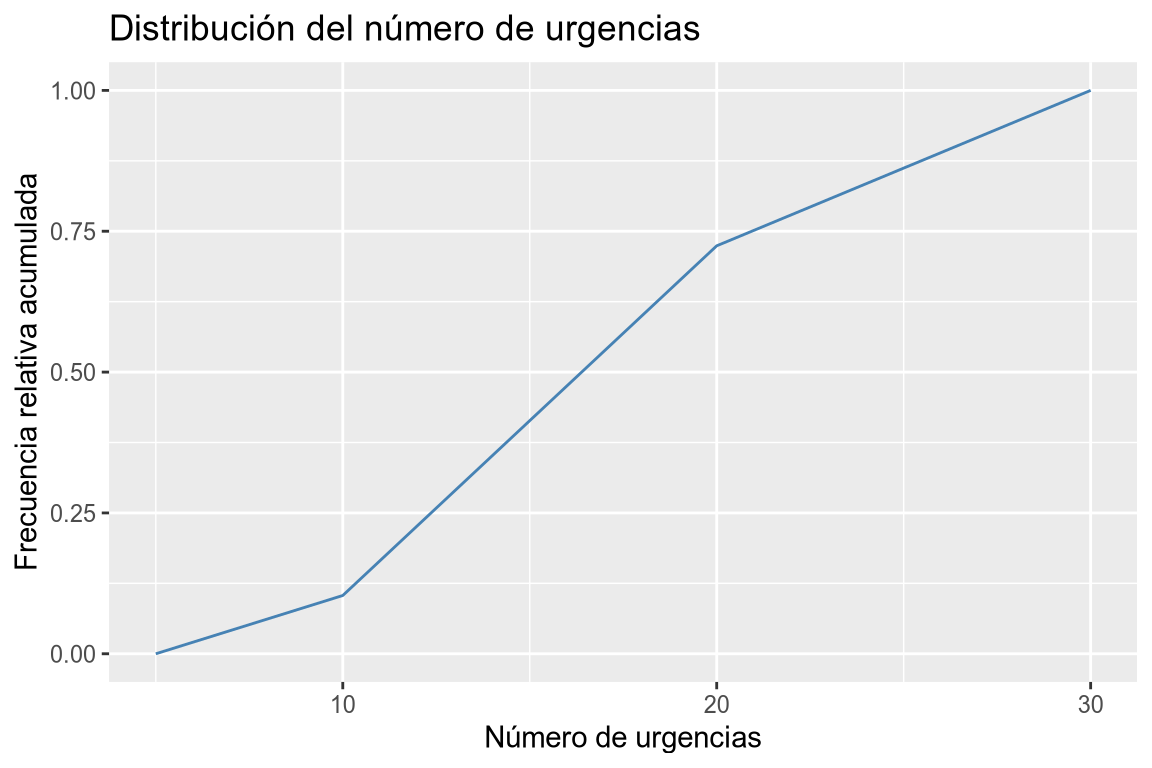
Dibujar un diagrama de líneas con las frecuencias relativas acumuladas (ojiva) de la columna urgencias del data frame df agrupando en 5 clases desde 5 hasta 30. -
Ejercicio 4.3 Los grupos sanguíneos de una muestra de 30 personas son:
| A | B | B | A | AB | 0 | 0 | A | B | B | A | A | A | A | AB |
| A | A | A | B | 0 | B | B | B | A | A | A | 0 | A | AB | 0 |
-
Crear un conjunto de datos con la variable
grupo_sanguíneo.TipSolucióndf <- data.frame(grupo_sanguineo = c("A", "B", "B", "A", "AB", "0", "0", "A", "B", "B", "A", "A", "A", "A", "AB", "A", "A", "A", "B", "0", "B", "B", "B", "A", "A", "A", "0", "A", "AB", "0"))Crear un data frame df con una columna grupo_sanguineo con los siguientes datos de grupos sanguíneos de una muestra de 30 personas: A, B, B, A, AB, 0, 0, A, B, B, A, A, A, A, AB, A, A, A, B, 0, B, B, B, A, A, A, 0, A, AB y 0. -
Construir la tabla de frecuencias.
TipSoluciónPara obtener las frecuencias absolutas se puede usar la función
table, y para las frecuencias relativas la funciónprop.tableambas del paquete base de R.Para obtener la tabla de frecuencias absolutas podemos usar la función
countdel paquetedplyrdetidyverse.Posteriormente podemos añadir nuevas columnas a la tabla de frecuencias mediante la función
mutatey la fórmula para calcular las frecuencias relativas (n/sum(n)).Crear una tabla de frecuencias con las frecuencias absolutas (ni) y relativas (fi) de la columna grupo_sanguineo del data frame df. -
Dibujar el diagrama de sectores.
TipSoluciónPara dibujar el diagrama de sectores podemos usar la función
piedel paquetegraphics.Parámetros:
-
x: vector con las frecuencias. -
col: vector con los colores de los sectores. -
main: título del gráfico.
Para dibujar el diagrama de sectores podemos usar la función
geom_bary después la funcióncoor_polardel paqueteggplot2detidyverse.Parámetros:
-
theta= Dimensión que contiene las frecuencias.
# Añadimos la variable a la dimensión fill, y dejamos la dimensión x vacía. df |> ggplot(aes(x = "", fill = grupo_sanguineo)) + # Añadimos la geometría de barras. geom_bar(color = "white") + # Cambiamos a coordenadas polares. coord_polar(theta = "y") + # Añadimos el título y las etiquetas de los ejes. labs(title = "Distribución de los grupos sanguíneos", fill = "Grupo sanguíneo") + # Eliminamos los ejes y el fondo del gráfico. theme_void()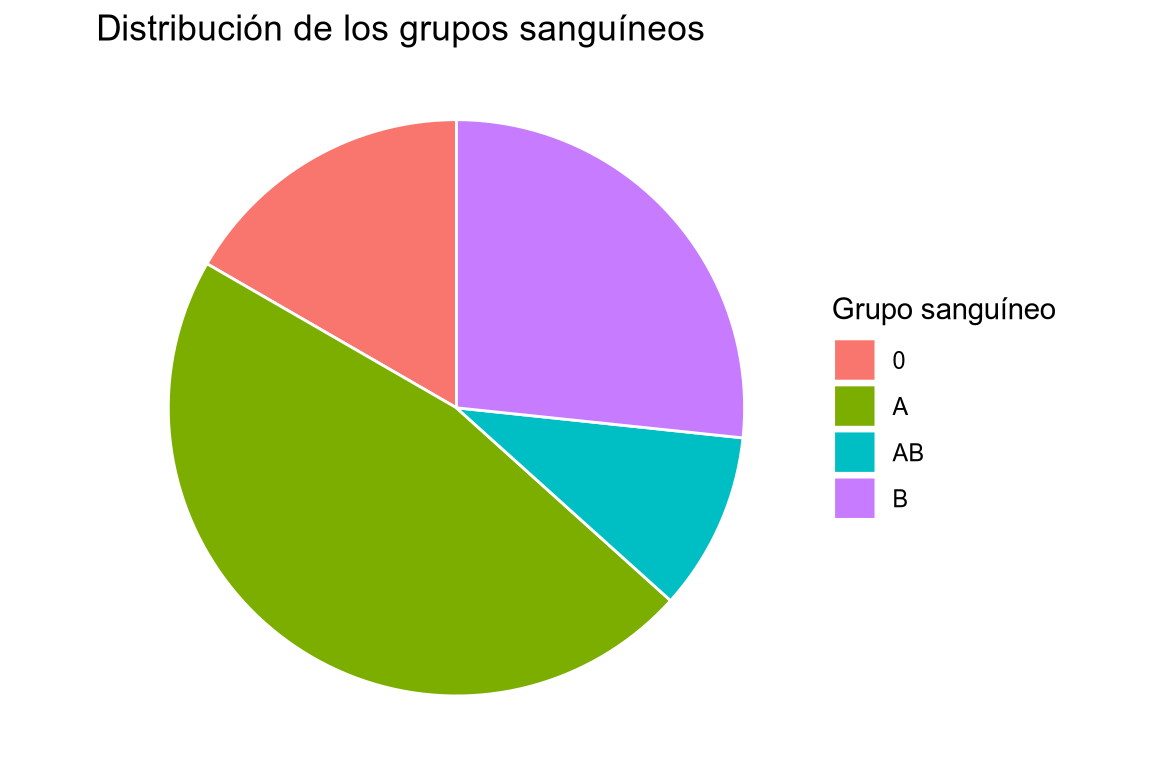
Dibujar un diagrama de sectores con la columna grupo_sanguineo del data frame df. -
Ejercicio 4.4 En un estudio de población se tomó una muestra de 27 personas, y se les preguntó por su edad y estado civil, obteniendo los siguientes resultados:
| Estado civil | Edad |
|---|---|
| Soltero | 31, 45, 35, 65, 21, 38, 62, 22, 31 |
| Casado | 62, 39, 62, 59, 21, 62 |
| Viudo | 80, 68, 65, 40, 78, 69, 75 |
| Divorciado | 31, 65, 59, 49, 65 |
-
Crear un conjunto de datos con la variables
estado_civilyedad.TipSolucióndf <- data.frame( edad = c(31, 45, 35, 65, 21, 38, 62, 22, 31, 62, 39, 62, 59, 21, 62, 80, 68, 65, 40, 78, 69, 75, 31, 65, 59, 49, 65), estado_civil = rep(c("Soltero", "Casado", "Viudo", "Divorciado"), c(9, 6, 7, 5)))Crear un data frame df con dos columnas edad y estado_civil. La columna edad con los siguientes datos: 31, 45, 35, 65, 21, 38, 62, 22, 31, 62, 39, 62, 59, 21, 62, 80, 68, 65, 40, 78, 69, 75, 31, 65, 59, 49 y 65. Y la columna estado_civil con los siguientes datos de estado civil: Soltero para las primeras 9 personas, Casado para las siguientes 6 personas, Viudo para las siguientes 7 personas y Divorciado para las últimas 5 personas. -
Calcular las frecuencias absolutas del
estado_civil.TipSoluciónCalcular las frecuencias absolutas de la columna estado_civil del data frame df. -
Construir la tabla de frecuencias de la variable
edadpara cada categoría de la variableestado_civil.TipSoluciónPara construir la tabla de frecuencias de una columna de un data frame para cada categoría de otra columna podemos usar las siguientes funciones del paquete
dplyrdetidyverse:group-by(df, columna). Agrupa el data frame por lacolumnaindicada.count(df, columna). Devuelve un data frame con las frecuencias absolutas de cada valor de la columna especificada.
# Añadimos una nueva columna al data frame con la clase a la que pertenece cada individuo, tomando intervalos de amplitud 10 desde 20 hasta 80. df |> mutate(edad_int = cut(edad, breaks = seq(20, 80, 10))) |> # Agrupamos por estado civil. group_by(estado_civil) |> # Calculamos las frecuencias absolutas. count(edad_int, name = "ni") |> # Añadimos nuevas columnas con las frecuencias relativas, acumuladas y relativas acumuladas. mutate(fi = ni/sum(ni), Ni = cumsum(ni), Fi = cumsum(ni)/sum(ni)) |> kable()estado_civil edad_int ni fi Ni Fi Casado (20,30] 1 0.1666667 1 0.1666667 Casado (30,40] 1 0.1666667 2 0.3333333 Casado (50,60] 1 0.1666667 3 0.5000000 Casado (60,70] 3 0.5000000 6 1.0000000 Divorciado (30,40] 1 0.2000000 1 0.2000000 Divorciado (40,50] 1 0.2000000 2 0.4000000 Divorciado (50,60] 1 0.2000000 3 0.6000000 Divorciado (60,70] 2 0.4000000 5 1.0000000 Soltero (20,30] 2 0.2222222 2 0.2222222 Soltero (30,40] 4 0.4444444 6 0.6666667 Soltero (40,50] 1 0.1111111 7 0.7777778 Soltero (60,70] 2 0.2222222 9 1.0000000 Viudo (30,40] 1 0.1428571 1 0.1428571 Viudo (60,70] 3 0.4285714 4 0.5714286 Viudo (70,80] 3 0.4285714 7 1.0000000 Construir una tabla de frecuencias con las frecuencias absolutas (ni), relativas (fi), acumuladas (Ni) y relativas acumuladas (Fi) de la columna edad agrupando en intervalos de amplitud 10 desde 20 hasta 80 para cada categoría de la columna estado_civil del data frame df. -
Dibujar los diagramas de cajas de la edad según el estado civil. ¿Existen datos atípicos? ¿En qué grupo hay mayor dispersión?
TipSoluciónPara dibujar un diagrama de caja y bigotes podemos usar la función
boxplotdel paquetegraphics.Parámetros:
-
formula: fórmula que relaciona la variable dependiente con la variable independiente (en este casoedad ~ estado_civil). -
data: data frame con los datos. -
col: color de la caja. -
horizontal: orientación horizontal de la caja (True o False). -
width: anchura de la caja (valor entre 0 y 1). -
main: título del gráfico. -
xlab: etiqueta del eje x. -
ylab: etiqueta del eje y.
boxplot(edad ~ estado_civil, data = df, horizontal = T, col = "steelblue", main = "Distribución de la edad según el estado civil", xlab = "Edad", ylab = "Estado civil")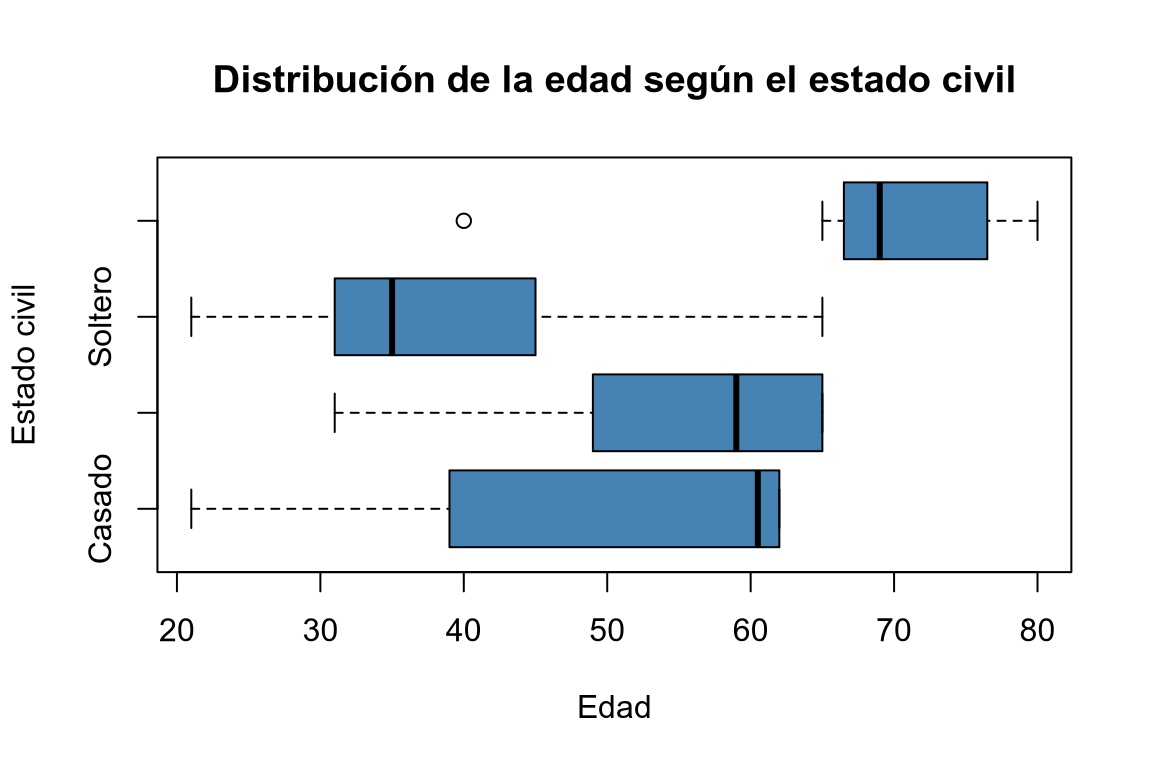
Para dibujar un diagrama de caja y bigotes podemos usar la función
geom_boxplotdel paqueteggplot2detidyverse.Parámetros:
- color: color del borde de la caja.
- fill: factor con las categorías que dividen en grupos las cajas (en este caso
estado_civil). Dibuja una caja por cada categoría. - width: anchura de la caja (valor entre 0 y 1).
# Añadimos la variable a la dimensión x y el estado civil a la dimensión fill. df |> ggplot(aes(x = edad, fill = estado_civil)) + # Añadimos la geometría de cajas. geom_boxplot() + # Eliminamos las marcas del eje y. scale_y_continuous(breaks = NULL) + # Añadimos el título y las etiquetas de los ejes y leyenda. labs(title = "Distribución de la edad según el estado civil", x = "Edad", fill = "Estado civil")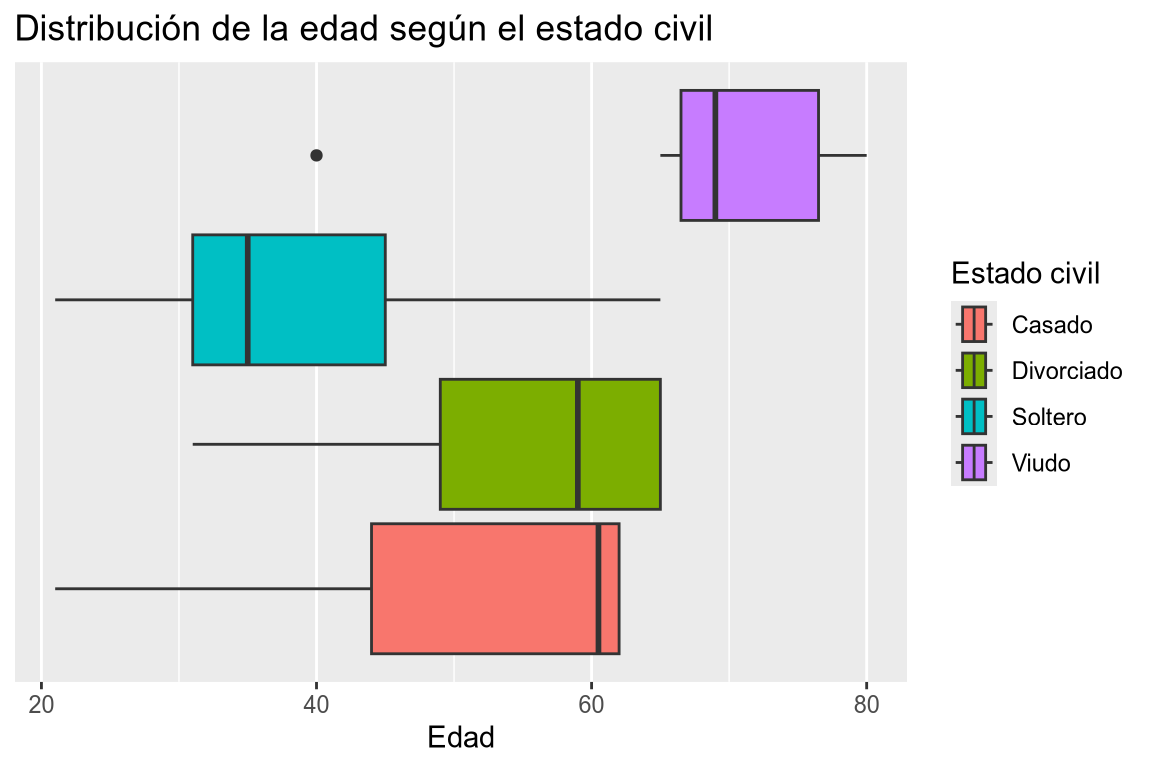
Dibujar un diagrama de cajas de la columna edad según las categorías de la columna estado_civil del data frame df. Usar un color diferente para cada categoría de la columna estado_civil. -
-
Dibujar los histogramas de la edad según el estado civil tomando clases de amplitud 10 desde 20 hasta 80.
TipSoluciónPara dibujar un histograma podemos usar la función
geom_histogramdel paqueteggplot2detidyverse.Parámetros:
-
breaks: Un vector con los puntos de corte de los intervalos de las barras. -
color: Color del borde de las barras. -
fill: factor con las categorías que dividen en grupos las cajas (en este casoestado_civil). Dibuja una caja por cada categoría. -
position: Posición de las barras (“identity” para superponer las barras, “stack” para apilar las barras y “dodge” para que las barras no se superpongan). -
alpha: Transparencia de las barras (valor entre 0 y 1).
# Añadimos la variable a la dimensión x y el estado civil a la dimensión fill. df |> ggplot(aes(x = edad, fill = estado_civil)) + # Añadimos la geometría de histograma creando clases de amplitud 10 desde 20 hasta 80. geom_histogram(breaks = seq(20, 80, 10), position = "stack") + # Añadimos el título y las etiquetas de los ejes. labs(title = "Distribución de la edad según el estado civil", x = "Edad", y = "Frecuencia", fill = "Estado civil")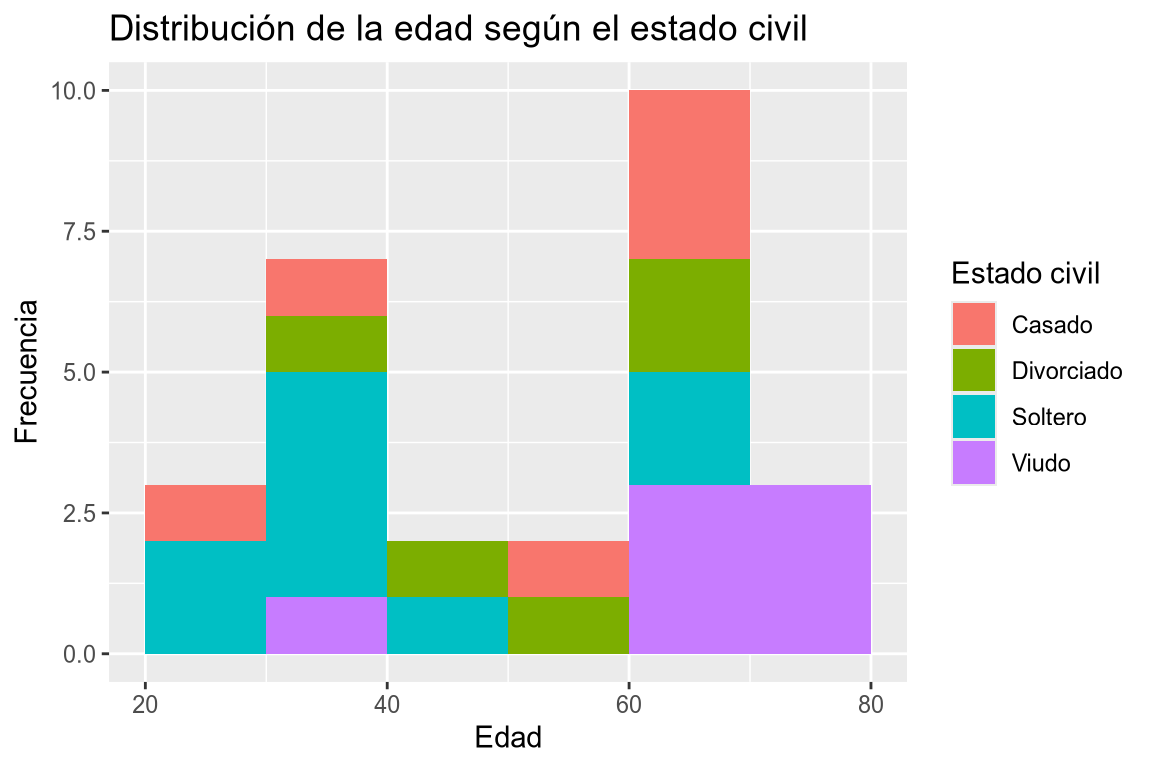
Para dibujar cada histograma por separado se puede usar la función
facet_wrapofacet_griddel paqueteggplot2detidyverse.# Añadimos la variable a la dimensión x y el estado civil a la dimensión fill. df |> ggplot(aes(x = edad, fill = estado_civil)) + # Añadimos la geometría de histograma creando clases de amplitud 10 desde 20 hasta 80. geom_histogram(breaks = seq(20, 80, 10)) + # Añadimos facetas el estado civil. facet_wrap(~ estado_civil) + # Añadimos el título y las etiquetas de los ejes. labs(title = "Distribución de la edad según el estado civil", x = "Edad", y = "Frecuencia", fill = "Estado civil")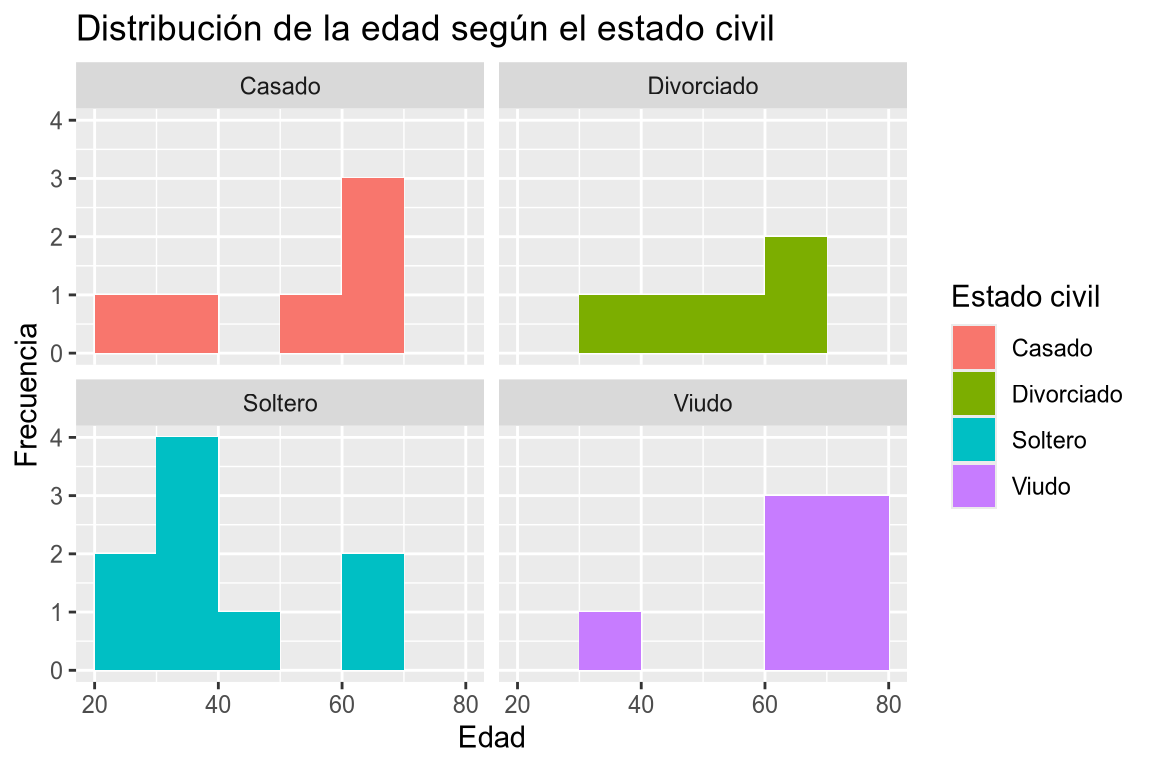
Dibujar un histograma de la columna edad para cada categoría de la columna estado_civil del data frame df tomando intervalos de amplitud 10 desde 20 hasta 80. Usar facetas y colores de relleno diferentes para cada categoría de la columna estado_civil. -
4.2 Ejercicios propuestos
Ejercicio 4.5 El número de lesiones padecidas durante una temporada por cada jugador de un equipo de fútbol fue el siguiente:
| 0 | 1 | 2 | 1 | 3 | 0 | 1 | 0 | 1 | 2 | 0 | 1 |
| 1 | 1 | 2 | 0 | 1 | 3 | 2 | 1 | 2 | 1 | 0 | 1 |
Construir la tabla de frecuencias.
Dibujar el diagrama de barras de las frecuencias relativas y de frecuencias relativas acumuladas.
Dibujar el diagrama de sectores.
Ejercicio 4.6 Para realizar un estudio sobre la estatura de los estudiantes universitarios, seleccionamos, mediante un proceso de muestreo aleatorio, una muestra de 30 estudiantes, obteniendo los siguientes resultados (medidos en centímetros):
| 179 | 173 | 181 | 170 | 158 | 174 | 172 | 166 | 194 | 185 |
| 162 | 187 | 198 | 177 | 178 | 165 | 154 | 188 | 166 | 171 |
| 175 | 182 | 167 | 169 | 172 | 186 | 172 | 176 | 168 | 187 |
Dibujar el histograma de las frecuencias absolutas agrupando desde 150 a 200 en clases de amplitud 10.
Dibujar el diagrama de cajas. ¿Existe algún dato atípico?
Ejercicio 4.7 El conjunto de datos neonatos contiene información sobre una muestra de 320 recién nacidos en un hospital durante un año que cumplieron el tiempo normal de gestación.
Construir la tabla de frecuencias de la puntuación Apgar al minuto de nacer. Si se considera que una puntuación Apgar de 3 o menos indica que el neonato está deprimido, ¿qué porcentaje de niños está deprimido en la muestra?
Comparar las distribuciones de frecuencias de las puntuaciones Apgar al minuto de nacer según si la madre es mayor o menor de 20 años. ¿En qué grupo hay más neonatos deprimidos?
Construir la tabla de frecuencias para el peso de los neonatos, agrupando en clases de amplitud 0.5 desde el 2 hasta el 4.5. ¿En qué intervalo de peso hay más neonatos?
Comparar la distribución de frecuencias relativas del peso de los neonatos según si la madre fuma o no. Si se considera como peso bajo un peso menor de 2.5 kg, ¿En qué grupo hay un mayor porcentaje de niños con peso bajo?
Construir el diagrama de barras de la puntuación Apgar al minuto. ¿Qué puntuación Apgar es la más frecuente?
Construir el diagrama de frecuencias relativas acumuladas de la puntuación Apgar al minuto. ¿Por debajo de que puntuación estarán la mitad de los niños?
Comparar mediante diagramas de barras de frecuencias relativas las distribuciones de las puntuaciones Apgar al minuto según si la madre ha fumado o no durante el embarazo. ¿Qué se puede concluir?
Construir el histograma de pesos, agrupando en clases de amplitud 0.5 desde el 2 hasta el 4.5. ¿En qué intervalo de peso hay más niños?
Comparar la distribución de frecuencias relativas del peso de los neonatos según si la madre fuma o no. ¿En qué grupo se aprecia menor peso de los niños de la muestra?
Comparar la distribución de frecuencias relativas del peso de los neonatos según si la madre fumaba o no antes del embarazo. ¿Qué se puede concluir?
Construir el diagrama de caja y bigotes del peso. ¿Entre qué valores se considera que el peso de un neonato es normal? ¿Existen datos atípicos?
Comparar el diagrama de cajas y bigotes del peso, según si la madre fumó o no durante el embarazo y si era mayor o no de 20 años. ¿En qué grupo el peso tiene más dispersión central? ¿En qué grupo pesan menos los niños de la muestra?
Comparar el diagrama de cajas de la puntuación Apgar al minuto y a los cinco minutos. ¿En qué variable hay más dispersión central?