|
Variables independientes
|
Variable dependiente
|
Objetivo
|
Ejemplo
|
Contraste
|
|
Ninguna
(Una población)
|
Cuantitativa
|
Contrastar la normalidad de una variable
|
Comprobar si la nota de un examen tiene distribución normal (forma de campana de Gauss)
|
Komogorov-Smirnov
(requiere muestras grandes)
|
|
Shapiro-Willks
|
|
Cuantitativa normal
|
Contrastar si la media poblacional de una variable tiene un valor determinado
|
Comprobar si la nota media de un examen es 5
|
Test T para la media de una población
|
|
Cuantitativa o cualitativa ordinal
|
Contrastar si la mediana poblacional de una variable tiene un valor determinado
|
Comprobar si la calificación mediana de un examen es Aprobado
|
Test para la mediana de una población
|
|
Cualitativa (2 categorías)
|
Contrastar si la proporción poblacional de una de las categorías tiene un valor determinado
|
Comprobar si la proporción de aprobados es de la mitad (o que el porcentaje es 50%)
|
Test Binomial
|
|
Cualitativa
|
Contrastar si las proporciones de cada una de las categorías tienen un valor determinado
|
Comprobar si las proporciones de alumnos matriculados en ciencias, letras o mixtas son 0.5, 0.2 y 0.3 respectivamente
|
Test Chi-cuadrado de bondad de ajuste
|
|
Una cualitativa con dos categorías independientes
(Dos poblaciones independientes)
|
Cuantitativa normal
|
Contrastar si hay diferencias entre las medias la variable dependiente en dos poblaciones independientes
|
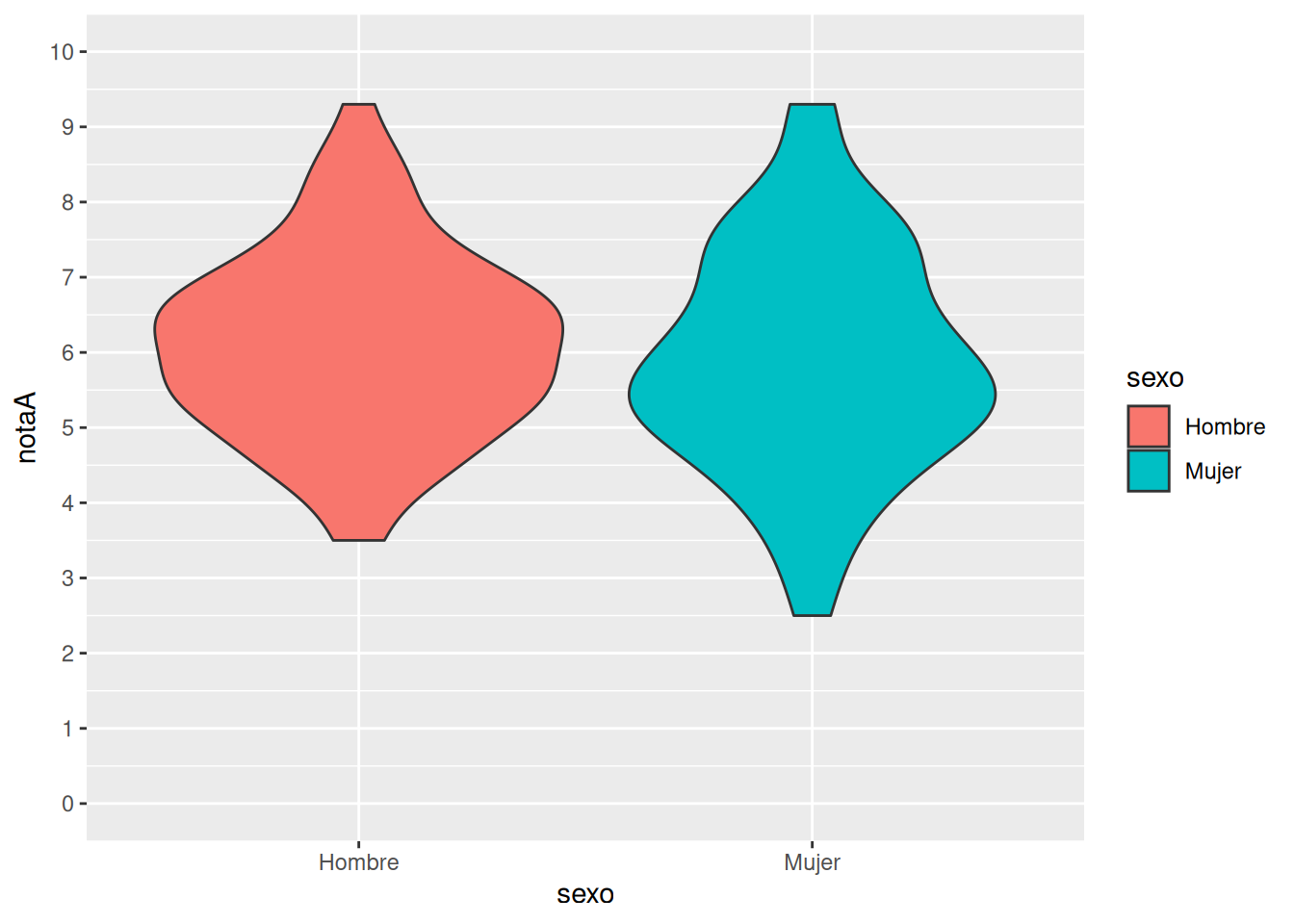
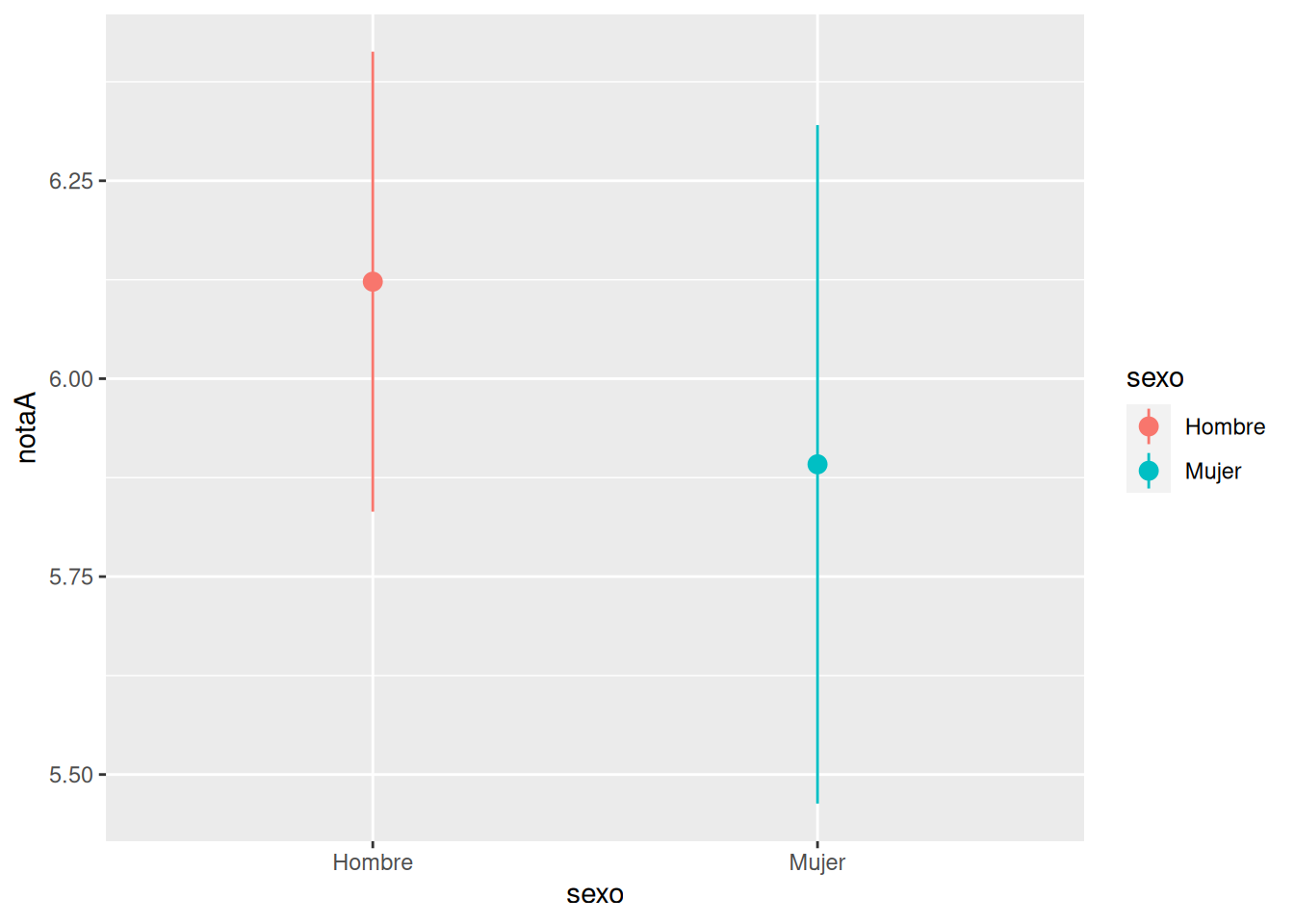
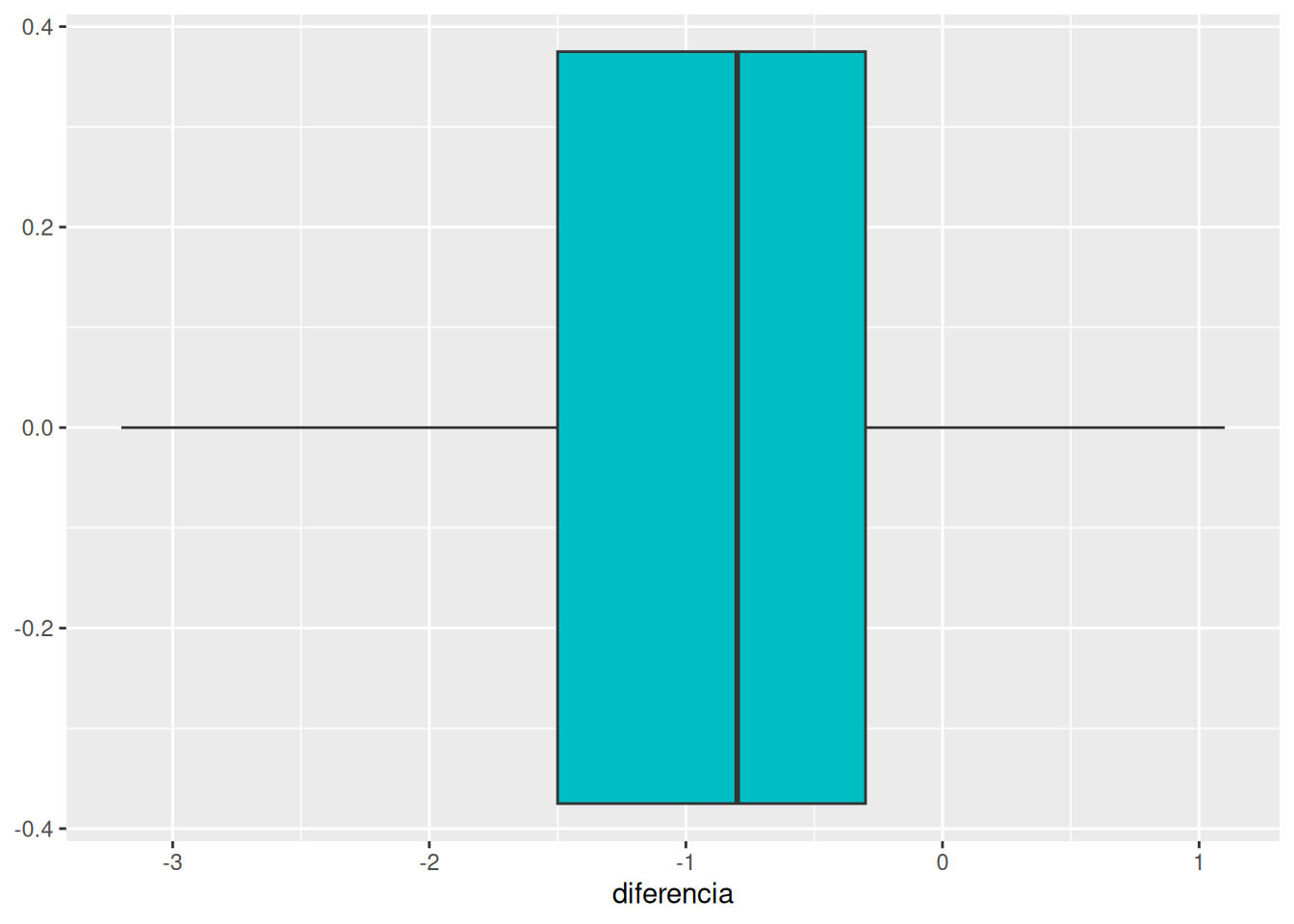
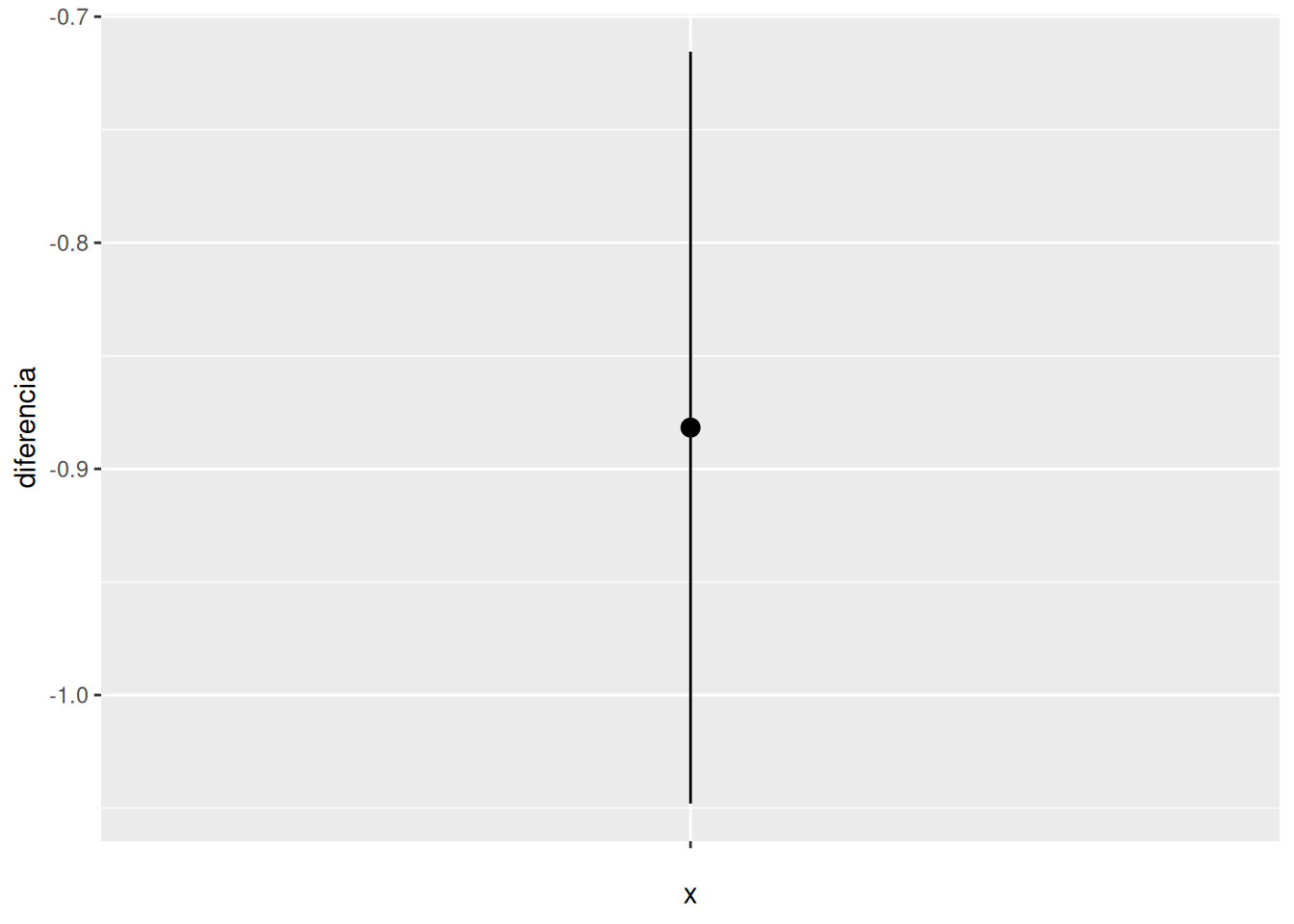
Comprobar si el grupo de mañana y el grupo de tarde han tenido notas medias diferentes
|
Test T para la comparación de medias de poblaciones independientes
|
|
Contrastar si hay diferencias entre las varianzas de la variable dependiente en dos poblaciones independientes
|
Comprobar si hay diferencias entre la variabilidad de las notas del grupo de mañana y el de tarde
|
Test F de Fisher
|
|
Contrastar si hay concordancia o acuerdo entre las dos variables
|
Comprobar si hay concordancia o acuerdo entre las notas que ponen dos profesores distintos para los mismos exámenes
|
Correlación intraclase
|
|
Cuantitativa o cualitativa ordinal
|
Contrastar si hay diferencias entre las distribuciones de la variable dependiente en dos poblaciones independientes
|
Comprobar si el grupo de mañana y el grupo de tarde han tenido calificaciones diferentes
|
Test de la U de Mann-Whitney
|
|
Contrastar si hay concordancia o acuerdo entre las dos variables
|
Comprobar si hay concordancia o acuerdo entre las calificaciones que ponen dos profesores distintos para los mismos exámenes
|
Kappa de Cohen
|
|
Cualitativa
|
Contrastar si hay relación entre las dos variables o bien si hay diferencias entre las proporciones de las categorías de la variable dependiente en las dos poblaciones definidas por las categorías de la variable independiente
|
Comprobar si existe relación entre los aprobados en una asignatura y el grupo al que pertenecen los alumnos, es decir, si la proporción de aprobados es diferente en dos grupos distintos.
|
Test Chi-cuadrado
(si no ha más del 20% de frecuencias esperadas menores que 5)
Test exacto de Fisher
|
|
Contrastar si hay concordancia o acuerdo entre las dos variables
|
Comprobar si hay concordancia o acuerdo entre la valoración (aprobado o suspenso) que hacen dos profesores distintos para los mismos exámenes
|
Kappa de Cohen
|
|
Una cualitativa con dos categorías relacionadas o pareadas
(Dos poblaciones relacionadas o pareadas)
|
Cuantitativa normal
|
Contrastar si hay diferencias entre las medias de la variable dependiente en dos poblaciones relacionadas o pareadas
|
Comprobar si las notas medias de dos asignaturas cursadas por los mismos alumnos han sido diferentes o si las notas medias de un examen realizado al comienzo del curso (antes) y otro al final (después) de una misma asignatura han sido diferentes
|
Test T para la comparación de medias de poblaciones relacionadas o pareadas
|
|
Cuantitativa o cualitativa ordinal
|
Contrastar si hay diferencias entre las distribuciones de la variable dependiente en dos poblaciones relacionadas o pareadas
|
Comprobar si las calificaciones de dos asignaturas cursadas por los mismos alumnos han sido diferentes
|
Test de Wilcoxon
|
|
Cualitativa con dos categorías
|
Contrastar si hay diferencias entre las proporciones de las categorías de la variable dependiente en dos poblaciones relacionadas o pareadas
|
Comprobar si la proporción o el porcentaje de aprobados en un examen es distinta al comienzo y al final del curso
|
Test de McNemar
|
|
Una cualitativa con dos o más categorías
independientes
(Dos o más poblaciones independientes)
|
Cuantitativa normal y homogeneidad de varianzas
|
Contrastar si hay diferencias entre las medias la variable dependiente en cada una de las poblaciones definidas por las categorías de la variable independiente
|
Comprobar si existen diferencias entre las notas medias de tres grupos distintos de clase.
|
Análisis de la Varianza de un factor (ANOVA)
Si hay diferencias > Test de Tukey o Bonferroni para la diferencia por pares
|
|
Cuantitativa normal
|
Contrastar si hay diferencias entre las varianzas de la variable dependiente en cada una de las poblaciones definidas por las categorías de la variable independiente
|
Comprobar si la variabilidad de las notas de una asignatura es distinta en tres grupos diferentes de clase
|
Prueba de Levene para la homogeneidad de varianzas
|
|
Cuantitativa o cualitativa ordinal
|
Contrastar si hay diferencias entre las distribuciones de la variable dependiente en cada una de las poblaciones definidas por las categorías de la variable independiente
|
Comprobar si existen diferencias entre las calificaciones de tres grupos distintos de clase
|
Test de Kruskal Wallis
|
|
Cualitativa
|
Contrastar si hay relación entre las dos variables o bien si hay diferencias entre las proporciones de las categorías de la variable dependiente en cada una de las poblaciones definidas por las categorías de la variable independiente
|
Comprobar si existe relación entre los aprobados en una asignatura y el grupo al que pertenecen los alumnos, es decir, si la proporción de aprobados es diferente en los distintos grupos.
|
Test Chi-cuadrado
(si no ha más del 20% de frecuencias esperadas menores que 5)
Test exacto de Fisher
|
|
Una cualitativa con dos o más categorías relacionadas
(medidas repetidas)
|
Cuantitativa normal
|
Contrastar si hay diferencias entre las medias repetidas de la variable dependiente
|
Comprobar si hay diferencias entre las notas que otorgan varios profesores a un mismo examen
|
Análisis de la Varianza (ANOVA) de medidas repetidas de un factor
|
|
Cuantitativa o cualitativa ordinal
|
Contrastar si hay diferencias entre las medidas repetidas de la variable dependiente
|
Comprobar si hay diferencias entre las calificaciones que otorgan varios profesores a un mismo examen
|
Test de Friedman
|
|
Cualitativa
|
Contrastar si hay diferencias entre las valoraciones repetidas de la variable dependiente
|
Comprobar si hay diferencias entre la valoración (aprobado o suspenso) que hacen varios profesores de un mismo examen
|
Regresión logística de medidas repetidas
|
|
Una cuantitativa normal
|
Cuantitativa normal
|
Contrastar si existe relación lineal entre las dos variables
|
Comprobar si existe relación entre las notas de dos asignaturas
|
Correlación de Pearson
|
|
Construir un modelo predictivo que explique la variable dependiente en función de la independiente
|
Construir el modelo (función de regresión) que mejor explique la relación entre la nota de un examen y las horas dedicadas a su estudio
|
Regresión simple (lineal o no lineal)
|
|
Cuantitativa o cualitativa ordinal
|
Contrastar si existe relación lineal entre las dos variables
|
Comprobar si existe relación entre las calificaciones de dos asignaturas
|
Correlación de Spearman
|
|
Cualitativa
|
Construir un modelo predictivo que explique la variable dependiente en función de la independiente
|
Construir el modelo (función logística) que mejor explique la relación entre el resultado de un examen (aprobado o suspenso) y las horas dedicadas a su estudio
|
Regresión logística simple
|